Наиболее часто используемыми статистическими процедурами являются PROC MEANS и PROC FREQ. Данный урок направлен на изучение базовых понятий и вариантов применения этих процедур. Начнём с PROC MEANS
PROC MEANS
Общий обзор
PROC MEANS используется во множестве аналитических ситуаций. Из названия процедуры становится понятным, что используют ее как минимум для подсчёта среднего значения (MEAN). На самом же деле процедура используется для подсчёта целого ряда так называемых описательных статистик (descriptive statistics). Бизнес аналитики и программисты используют возможности этой процедуры для:
- Описания непрерывных данных, где средняя величина имеет значение
- Описания средних величин в пределах групп (указанных в «by» или «classification» statement процедуры PROC MEANS)
- Поиска возможных «outliers» или неправильно введенных/запрограммированных значений
Результаты, полученные после выполнения процедуры могут быть:
- Направлены в Output Window системы SAS
- Сохранены в PDF, rtf либо HTML файл средствами Output Delivery System (ODS)
- Сохранены в виде SAS датасетов, которые в дальнейшем могут быть использованы другими процедурами либо экспортированы в CSV файл
Ключевые термины и понятия
PROC MEANS входит в базовый (BASE) модуль программной системы SAS. В рамках этой процедуры термин «анализируемая переменная» (analysis variable) подразумевает числовую (numeric) переменную (либо переменные), значения которой мы хотим проанализировать. Переменные, которые используются для группировки – «classification variable(s)» (указанные в «by» или «classification» statement) могут быть как числовые (numeric), так и строковые (character); значения таких переменных могут быть использованы для классификации результатов анализа «анализируемой переменной». Например, если вы хотите проанализировать числовую переменную SALARY (оклад) по полу (GENDER), то «анализируемой переменной» будет SALARY, а GENDER будет выступать в роли классификатора (classification variable). Результатом выполнения PROC MEANS является набор статистик (statistics), который вы также можете задавать, используя так называемые «statistics keyword». Т.е. если вам нужно подсчитать среднее значение (MEAN) и медиану (MEDIAN) для SALARY по GENDER, то statistics keywords «MEAN» и «MEDIAN» должны быть указаны при вызове PROC MEANS. (Полный список «statistics keywords» и их правильное размещение в синтаксисе PROC MEANS описывается далее.) Также в этом уроке будут использованы такие понятия как «input data set» (входной набор данных) – исходный набор данных, наблюдения (observations) и переменные (variables) которого будут использованы при вызове PROC MEANS; и «output data set» (выходной набор данных) – SAS датасет, созданный PROC MEANS и включающий в себя результаты анализа.
Базовый синтаксис процедуры
Базовый синтаксис процедуры такой:
PROC MEANS <option(s)> <statistic-keyword(s)>; WHERE <condition>; BY <DESCENDING> variable-1 <… <DESCENDING> variable-n><NOTSORTED>; CLASS variable(s) </ option(s)>; OUTPUT <OUT=SAS-data-set> <output-statistic-specification(s)></option(s)>; VAR variable(s); RUN;
Давайте рассмотрим назначение каждого оператора (выделены синим выше). Итак,
- PROC MEANS: инициализирует вызов процедуры;
- WHERE: осуществляет отбор по условию (<condition>) из input data set;
- BY: создает отдельный набор статистик для каждой BY группы (переменной или набора переменных); как видно из базового синтаксиса – by-переменные могут быть представлены не только в порядке возрастания, но и нисходящем порядке, указывая ключевое слово DESCENDING перед названием by-переменой; также можно воспользоваться ключевых словом NOTSORTED после имени by-переменной, в этом случае информация будет представлена в том порядке, в котором значения by-переменной идут в input data set; при использовании by-переменных input data set должен быть предварительно по ним отсортирован;
- CLASS: указывает переменные (classification variale(s)), значения которых определяют комбинации подгрупп для анализа; аналог оператора BY; предварительная сортировка input data set по CLASS переменным не требуется;
- OUTPUT: записывает результаты выполнения процедуры (descriptive statistics) в output SAS data set;
- VAR: указывает одну или несколько анализируемых переменных и порядок их вывода;
- RUN: выполняет ранее введенные операторы SAS.
Далее рассмотрим описание опций по каждому оператору:
| Statement | Option | Description |
|---|---|---|
| PROC MEANS | DATA = SAS-data-set | Указывает исходный набор анализируемых данных (input data set) |
| Управление уровнями классификации | ||
| MISSING | Инструкция к использованию пустых (missing) значений classification переменных как валидных значений в процессе создания комбинаций этих classification переменных | |
| Управление выводом | ||
| NOOBS | Убирает из вывода общее количество наблюдений (observations) для каждой уникальной комбинации | |
| NOPRINT | При указании этой опции результаты, полученные с помощью PROC MEANS, не будут отображаться в Output Window | |
| ORDER=DATA | FORMATTED | FREQ | UNFORMATTED |
Упорядочивает значения classification переменных согласно выбранному порядку:
|
|
| Управление статистическим анализом
(descriptive statistic-keyword(s)) |
По умолчанию PROC MEANS считает такие статистики как N, MIN, MAX, MEAN и STD | |
| N | Количество наблюдений | |
| NMISS | Количество наблюдений с пустым результатом | |
| MEAN | Арифметическое среднее | |
| STD|STDDEV | Среднеквадратичное отклонение, часто встречается как SD (standard deviation | |
| MEDIAN|P50 | Медиана | |
| Q1|P25 | Первый квартиль | |
| Q3|P75 | Третий квартиль | |
| MIN | Минимум | |
| MAX | Максимум | |
| STDERR | Стандартная ошибка среднего | |
| CLASS | ASCENDING | Определяет сортировку значений CLASS переменных в возрастающем порядке |
| DESCENDING | Определяет сортировку значений CLASS переменных в нисходящем порядке | |
| OUTPUT | OUT = SAS-data-set | Определяет имя output data set. Если вы опустите OUT = , то дата сет будет назван DATAn, где n является целым числом (т.е. DATA1 или DATA2, если DATA1 уже существует) |
| Управление статистиками в output data set
(output-statistic-specification(s)) |
Указывает какие статистики нужно сохранить в OUT = data set и даёт имена переменным, которые будут содержать статистики. Форма записи такая: statistic-keyword
<(variable-list)>=
|
|
Вызов процедуры и описание результатов вывода
За основу возьмем input data set CLASS, содержащий информацию об учениках одного класса. Сохраним данные в input SAS data set используя DATA STEP и оператор DATALINES:
data class;
infile datalines dlm='|';
length name $10 sex $1 age height weight 8;
input name sex age height weight;
datalines;
John|M|12|159|55.7
Tony|M|12|157|53.1
Jeff|M|14|169|70.0
Anny|F|13|156|46.1
;
run;
Выполним DATA STEP. Получим input data set вида:
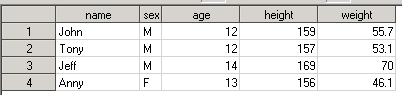
Теперь давайте посчитаем средний возраст учеников. Для этого вызовем PROC MEANS и укажем AGE как анализируемую переменную:
proc means data=class; var age; run;
Результат выполнения процедуры можно посмотреть в окне Output:

Итак, что же мы видим. В output вывелись 5 простых статистик. Количество учеников представлено статистикой N (N = 4 ученика). Минимальный возраст среди всех учеников класса представлен статистикой Minimum (Minimum = 12 лет), максимальный возраст – статистикой Maximum (Maximum = 14 лет). Среднее значение представлено Mean (Mean = 12.75 лет) и среднеквадратичное отклонение представлено Std Dev (SD = 0.9574271 лет). Следовательно, средний возраст 4 учеников класса составляет 12.75 лет.
Дальше давайте посчитаем средний возраст отдельно для мальчиков (SEX = M) и девочек (SEX = F). Для этого воспользуемся оператором CLASS:
proc means data=class; var age; class sex; run;
В окне Output увидим следующий результат:
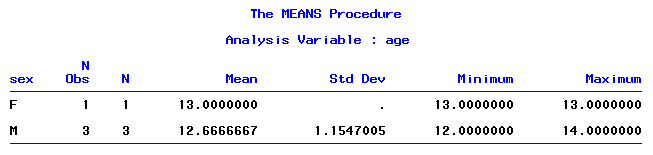
Итак, статистики посчитаны отдельно для мальчиков и девочек. По сравнению с первым output добавились 2 новые колонки: SEX – наш классификатор и N Obs – статистика, указывающая сколько наблюдений (observations) было задействовано при подсчёте среднего (N Obs можно убрать из Output используя опцию NOOBS в операторе PROC MEANS). Следовательно, средний возраст (он же минимальный и максимальный) 1 девочки составляет 13 лет, в то время, как средний возраст 3 мальчиков равен 12.67 лет.
Самое интересное в SAS это то, что практически в любой ситуации нужный нам результат можно получить несколькими способами. Так, например, средний возраст по половому признаку можно получить также при помощи использования оператора BY вместо CLASS. Единственное отличие состоит в том, что при использовании оператора BY input data set должен быть предварительно отсортирован по BY-переменной:
proc sort data=class; by sex; run;
proc means data=class; var age; by sex; run;
Output конечно же немного отличается, но смысл и результат остается неизменным:

При использовании BY в окне Output мы увидим отдельный набор статистик для каждого значения BY-переменной (sex=F and sex=M).
Теперь давайте разберемся с descriptive statistic-keyword(s). Допустим, нас интересует не только стандартный набор статистик, но и медиана. В таком случае нам нужно дать понять PROC MEANS какие именно статистики нас интересует. Делается это следующим образом: при вызове процедуры в операторе PROC MEANS указываем нужные нам статистики (в данном случае это N, MEAN, STD, MEDIAN, MIN and MAX):
proc means data=class n mean std median min max; var age; run;
Output будет выглядеть следующим образом:

Появилась еще одна колонка со статистикой Median (Median = 12.5 лет). Подобным образом можно «заказать» любую доступную статистику.
Сохранение результатов
Как говорилось ранее, результаты выполнения PROC MEANS можно сохранить либо в output SAS data set, либо сразу в файл, либо и то и другое одновременно.
Давайте сохраним наши результаты в output SAS data set и назовем его RESULTS. Для этого воспользуемся оператором OUTPUT и опцией OUT = <output data set>:
proc means data=class; var age; output out=results; run;
После выполнения процедуры в папке Work мы увидим датасет RESULTS, состоящий из 5 наблюдений (observations) и 4 переменных (variables):
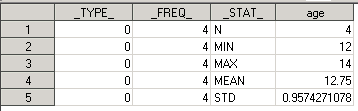
Где:
- _TYPE_ - это автоматическая переменная созданная SAS, содержит значение от 0 до n, что указывает на количество уникальных комбинаций CLASS переменных; _TYPE_ = 0 если CLASS переменная не указана (как у нас в примере), либо на записях с общими результатами по всем CLASS переменным;
- _FREQ_ - также автоматически созданная переменная; указывает количество наблюдений (observations) из input data set, использованных для подсчёта статистик;
- _STAT_ - переменная, в которой хранится название статистики;
- AGE – результирующая переменная, в которой хранится значение статистик; как видим значения переменной AGE по каждой из статистик совпадает с тем, что мы уже рассматривали в окне Output.
Давайте попробуем сохранить результаты PROC MEANS, но уже с использование разбиения по полу с помощью оператора CLASS:
proc means data=class; class sex; var age; output out=results_by_sex; run;
В папке Work появился датасет RESULTS_BY_SEX. В нем 15 observations и 5 переменных:
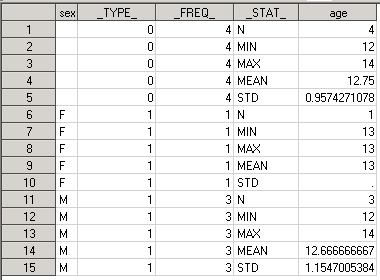
Где:
- SEX – наш классификатор; строки где SEX = F – это результаты для девочек, SEX = M – для мальчиков; строки, где SEX принимает пустое значение — это общие результаты по всем уровням CLASS переменных;
- _TYPE_ - принимает значение 0 на строках с общими результатами и 1 (по количеству уникальных комбинаций CLASS переменных – т.е. для одной CLASS переменной имеем одну уникальную комбинацию) на записях, где SEX заполнен;
- _FREQ_ - принимает значение 4 на строках с общими результатами, т.е. всего 4 записи из input data set были использованы при расчётах; для SEX = F значение _FREQ_ = 1 (т.е. из 4 учеников только одна девочка); для SEX = M значение _FREQ_ = 3 (т.е. из 4 учеников всего три мальчика);
- В переменных _STAT_ и AGE по-прежнему хранится название и значение статистик, но уже с разбивкой по полу.
Теперь давайте проделаем всё тоже самое, но используя оператор BY для разбиения по полу. Результат сохраним в датасет RESULTS_BY_SEX1:
proc sort data=class; by sex; run;
proc means data=class; by sex; var age; output out=results_by_sex1; run;
В папке Work ищем датасет с названием RESULTS_BY_SEX1. Что же мы видим:
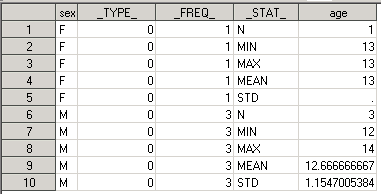
Количество записей равно 10, т.е. по сравнению с CLASS мы не видим секции с общими результатами по всей выборке. Переменная _TYPE_ = 0 на всех строках, т.к. вместо CLASS мы использовали BY.
Возникает вопрос – что же лучше использовать CLASS или BY. Конкретного и единственно правильного ответа не существует, т.к. всё зависит от того, что же вам нужно получить на выходе. Иными словами, если вам нужны общие результаты по какой-либо группе – можно воспользоваться CLASS, если же вас они не интересуют – делайте классификацию используя оператор BY.
Далее рассмотрим пример сохранения датасета с нестандартным набором статистик. Для этого в опциях оператора OUTPUT нам нужно указать сам набор желаемых статистик, а также описать имена переменных, в которых они будут храниться:
proc means data=class; var age; output out=results n=N mean=Mean std=SD median=Median min=Minimum max=Maximum; run;
Т.е. кол-во записей будет сохранено в переменной с именем N, среднее в переменной Mean, среднеквадратичное отклонение в переменной SD, медиана в Median, минимум в Minimum, максимум в Maximum.
В результате получим датасет RESULTS вида:

где значения статистик представлены горизонтально (отдельные переменные), а не вертикально (отдельные записи), как это было в прошлых примерах.
Если же вам нужно «перевернуть» структуру датасета, т.е. сохранить значения в строках, можно транспонировать датасет RESULTS с помощью вызова PROC TRANSPOSE:
proc means data=class; var age; output out=results n=N mean=Mean std=SD median=Median min=Minimum max=Maximum; run; proc transpose data=results out=results_tr; var N Mean SD Median Minimum Maximum; run;
В итоге получим датасет RESULTS_TR, в котором будут 6 записей (по кол-ву статистик) и 2 переменные _NAME_ и COL1:
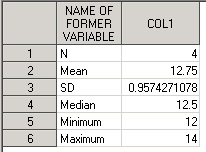
Где:
- _NAME_ - содержит имена транспонированных переменных (в нашем случае это названия статистик);
- COL1 – содержит значения транспонированных переменных (в нашем случае это значения статистик);
Еще один способ сохранить результаты поцедуры в датасет – воспользоваться возможностями Output Delivery System (ODS). Практически любая процедура SAS обладает набором так называемых ODS datasets, которые создаются автоматически в процессе использования процедуры. Для PROC MEANS одним из таких датасетов является датасет SUMMARY, в котором хранятся значения «заказанных» статистик. В этом варианте сохранения нам не нужен оператор OUTPUT, а сам синтаксис выглядит так:
ods output Summary=results; proc means data=class n mean std median min max; var age; run; ods output close;
Инструкция ODS OUTPUT открывает нам возможность манипулировать результатами вывода, а SUMMARY = RESULTS позволяет нам сохранить результаты выполнения процедуры в датасет в том виде, в котором они будут выведены в окне Output. В свою очередь инструкция ODS OUTPUT CLOSE закрывает направление вывода.
После выполнения вышеприведенного кода мы получим датасет RESULTS, который выглядит так:

где имена переменных следуют правилу <analysis var name>_<statistic name>, т.е. кол-во учеников хранится в переменной AGE_N, средний возраст в AGE_MEAN и т.д.
Итак, мы познакомились с разными вариантами сохранения результатов в датасет. Теперь давайте попробуем сохранить результаты в файл.
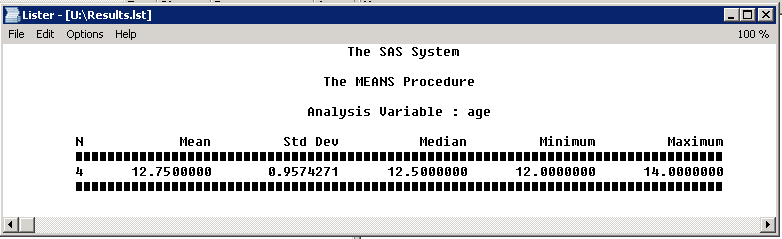
Если вам нужно сохранить результаты в обычном текстовом виде можно воспользоваться направлением ODS LISTING с опцией FILE:
ods listing file="U:\Results.lst"; proc means data=class n mean std median min max; var age; run;
где FILE = "<полный путь к файлу с расширением .lst>". В результате будет создан файл Results.lst и выглядеть он будет так:
Для того, чтобы сохранить результаты в RTF файл воспользуемся направлением RTF с опцией FILE:
ods rtf file="U:\Results.rtf"; proc means data=class n mean std median min max; var age; run; ods rtf close;
где FILE = "<полный путь к файлу с расширением .rtf>". В результате будет создан файл Results.rtf и выглядеть он будет так:

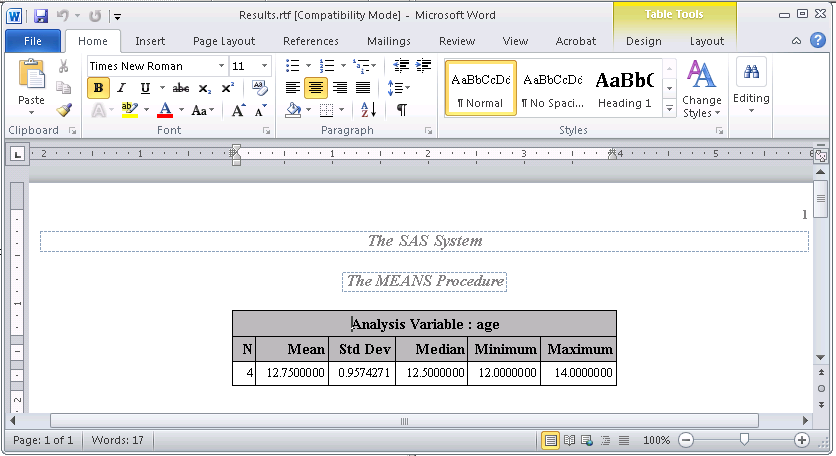
Тоже самое можно проделать для сохранения результатов в PDF (используя ODS PDF destination) и HTML (используя ODS HTML destination).
Теперь вы умеете сохранять результаты процедуры не только в виде датасета, но и в виде файла. На самом деле, специфика нашей работы такова, что сохранение результатов сразу в файл используется очень редко. В основном перед сохранением нам нужно отформатировать результаты, привести их к тому виду, который подходит заказчику. Далее мы поговорим о том, каким образом голые цифры превращаются в аналитический отчёт.
Форматирование (formatting) результатов
Начнём с постановки задачи. Итак, за основу возьмём датасет CLASS. Для создания полноценного отчёта нам нужно посчитать descriptive statistics (n, Mean, SD, Median, Min and Max) для таких переменных как возраст (AGE), вес (WEIGHT) и рост (HEIGHT) среди всех учащихся. Окончательный результат должен иметь вид:

Что же мы видим:
- конечный отчёт должен иметь 2 колонки (Characteristic и CLASS A) и 3 секции (Age (years), Weight (kg) и Height (cm)). Соответственно нам нужно подготовить data set, содержащий как минимум 2 переменные и 21 запись (по 7 записей на секцию);
- заголовки секций в колонке Characteristic (section titles), такие как Age (years), Weight (kg) и Height (cm) должны быть зрительно отделены от блока со статистиками небольшими отступами; согласитесь, так более читабельно;
- значения статистик в колонке CLASS A должны быть выровнены друг под другом по десятичной точке – это также упрощает чтение таблицы.
Задача поставлена. Давайте перейдем к реализации. Для этого вызовем PROC MEANS указав AGE, WEIGHT и HEIGHT как анализируемые переменные. Укажем нужные нам статистики, а также сохраним результаты в data set RESULTS при помощи ODS OUTPUT. Возьмите себе на заметку, что при использовании ODS OUTPUT мы можем сохранить значения статистик для всех анализируемых переменных за раз. Код имеет вид:
ods output summary=results; proc means data=class n mean std median min max; var age weight height; run; ods output close;
Давайте посмотрим, что у нас получилось. В датасете RESULTS содержится 1 запись и 21 переменная:
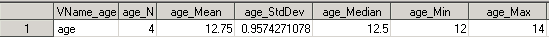


Т.е. мы получили датасет горизонтальной структуры, в котором кол-во переменных равно (кол-ву статистик + переменная содержащая имя analysis variable [VName_ < analysis variable>]) * 3 = 21.
Горизонтальная структура нам не подходит, ведь статистики в отчёте должны быть представлены вертикально, поэтому воспользуемся возможностями PROC TRANSPOSE. Транспонировать нам нужно все переменные, содержащие значения статистик (всего 18 переменных), соответственно все 18 нужно перечислить в операторе VAR. Зразу же возникает вопрос: какой нормальный человек будет писать руками список из 18 переменных? Это ж с ума сойти можно!? Ответ – никакой)! В SAS есть замечательная возможность для работы со списками переменных. Например, если вы хотите указать список переменных, имена которых начинаются на A, то синтаксис будет иметь вид «A:». В нашем случае мы должны указать в операторе VAR список из «AGE: WEIGHT: HEIGHT:», output data set назовем RESULTS_TR (results transposed):
proc transpose data=results out=results_tr; var age: weight: height:; run;
На выходе получим датасет вертикальной структуры:
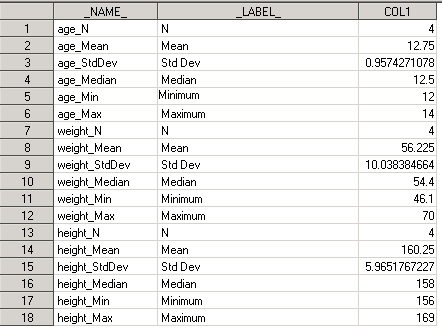
Где:
- _NAME_ - содержит имена транспонированных переменных;
- _LABEL_ - лейблы транспонированных переменных;
- COL1 – значения транспонированных переменных.
Данные готовы к форматированию. Следующим шагом давайте чётко выделим какие записи к какой переменной относятся. Интуитивно понятно, что всё, что имеет _NAME_ начинающийся на age – это статистики по AGE, weight – по WEIGHT и т.д, но сделать это нужно в явном виде – вам самим будет удобно; и в дальнейших преобразованиях это будет к месту. Сделаем это через DATA STEP след. образом: за основу возьмем переменную _NAME_ и отсканируем значения переменной до первого встреченного знака подчеркивания, сохраним это значение в переменную VARNAME в верхнем регистре (при помощи функции UPCASE):
data results_tr;
length varname $10;
set results_tr;
varname=upcase(scan(_name_,1,'_'));
run;
Имя переменной, к которой относится каждый набор статистик — это конечно же хорошо, но также полезно бы было иметь и порядковый номер переменной для дальнейшей работы с отчётом, т.е. как видно из задания, секция для AGE должна идти первой, за ней секция для WEIGHT и далее секция для HEIGHT. Введем переменную VARNO, сформируем ее с помощью информата (INFORMAT) и функции INPUT, основываясь на уже готовое значение переменной VARNAME:
proc format; invalue varno 'AGE'=1 'WEIGHT'=2 'HEIGHT'=3; run; data results_tr; length varname $10; set results_tr; varname=upcase(scan(_name_,1,'_')); varno=input(varname,varno.); run;
Получим датасет с 2-мя новыми переменными VARNAME и VARNO:
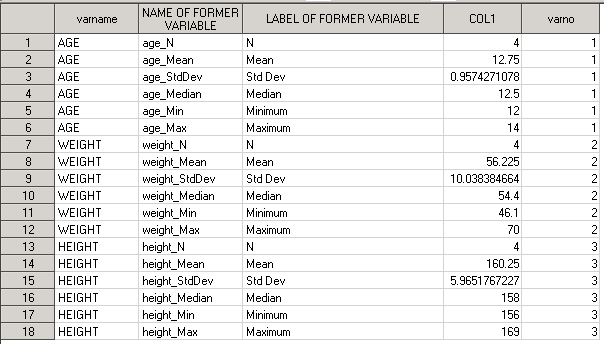
Далее сформируем переменную NAME_FORMATTED, в которой будут храниться форматированные названия статистик и заголовки секций. Воспользуемся строковым форматом (FORMAT) и фунцией PUT. За основу возьмем переменную _LABEL_. Как видно из задания, названия статистик отличаются только для N и Std Dev (N нужно представить в виде n, Std Dev в виде SD). Все остальные статистики имеют тот же вид, что и в переменной _LABEL_. Поэтому, чтобы не писать при создании формата, что ‘Mean’ = ‘Mean’, ‘Median’ = ‘Median’ воспользуемся ключевым словом OTHER = при создании формата. Другими словами, мы преобразуем N в n, Std Dev в SD, а все остальные значения переменной _LABEL_ будут PUT-нуты по формату (ширину формата регулируем по длине максимального значения, в нашем случае 20 символов будет достаточно для любого значения переменной _LABEL_).
proc format;
value $name_fmt
'N'='n'
'Std Dev'='SD'
other=[$20.];
run;
data results_tr;
length varname $10 name_formatted $50;
set results_tr;
varname=upcase(scan(_name_,1,'_'));
varno=input(varname,varno.);
name_formatted=put(_label_,$name_fmt.);
run;
Как и в случае с числовым представлением переменной VARNAME (а именно VARNO) нам будет удобно хранить порядковый номер статистики в переменной STATNO. Для этого создадим informat STATNO и воспользуемся функцией INPUT. За основу возьмем всё ту же переменную _ LABEL_:
proc format; invalue statno 'N'=1 'Mean'=2 'Std Dev'=3 'Median'=4 'Minimum'=5 'Maximum'=6; run; data results_tr; length varname $10 name_formatted $50; set results_tr; varname=upcase(scan(_name_,1,'_')); varno=input(varname,varno.); name_formatted=put(_label_,$name_fmt.); statno=input(_label_,statno.); run;
Результирующий датасет пополнится еще 2-мя переменными:
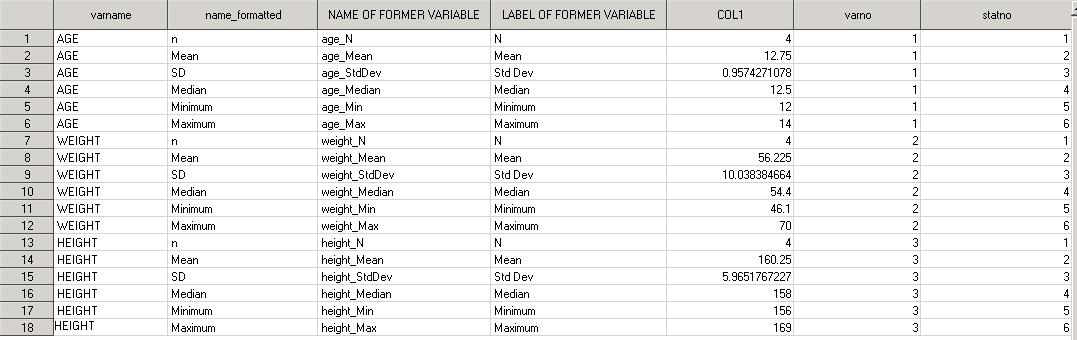
Итак, мы подошли к самому интересному – форматирования результатов (переменная COL1). Сразу проведем небольшой экскурс. SAS считает статистики с большой точностью - из нашего примера можно увидеть, что SD для AGE посчитано с 10 знаками после запятой. В реальной жизни вся эта «колбаса» никого не интересует, более того, при выводе в отчёт такое значение будет смотреться как минимум странно. Вы же не говорите, что SD для AGE составляет 0.9574271078; скорее всего вы скажете, что SD равно 0.96. Поэтому, рекомендую следовать следующему правилу при определении точности выводимых статистик:
- N – количество представителей выборки (в нашем случае учеников) всегда является целым числом;
- Mean – или среднее принято выводить с +1 знаком после запятой (в зависимости от точности исходных данных), т.е. если возраст указан в целых числах, то среднее будет иметь 1 знак после запятой; для веса Mean будет иметь 2 знака после запятой, т.к. исходные данные были измерены с точностью до десятых (55.7, 53.1 и т.д.);
- SD – принято выводить с +2 знаками после запятой (в зависимости от точности исходных данных);
- Median – выводим с +1 знаком, как и Mean;
- Min и Max – выводим с тем же кол-вом знаков, что и в исходных данных (т.е. для AGE как целые числа, для WEIGHT с 1 знаком).
Исходя из вышесказанного приступим к форматированию результатов. Для этого:
-
Определимся с позицией десятичной точки (DEC_POS) для вывода конечных результатов (чем больше это число, тем правее от края колонки будут выведены наши результаты). Пускай DEC_POS = 10, т.е. начиная с 11 символа будет выведена сама точка и далее дробная часть. На пальцах это выглядит так:
.........x
........xx.x
.........x.xxКод:
dec_pos=10;
-
Для каждой переменной (AGE, WEIGHT и HEIGHT) зададим точность исходных данных (original number of decimal places). Как видно из исходных данных AGE и HEIGHT – целые числа, а WEIGHT собрали с точностью до одного знака после запятой. Для этого воспользуемся соотв. информатом ORIG_DP (original decimal places) и функцией INPUT. За основу берем переменную VARNAME. Сохраним исходную точность в переменной ORIG_DP.
Код:
… invalue orig_dp 'AGE'=0 'WEIGHT'=1 'HEIGHT'=0; … orig_dp=input(varname,orig_dp.);
-
Тоже самое нужно проделать и для каждой статистики. Как было сказано выше Mean и Median выводим с +1 знаком, SD с +2 знаками, N – всегда целое, Min и Max в зависимости от точности исходных данных. Итак, создадим информат STAT_DP (number of decimal places for statistics). Назовем переменную STAT_DP. За основу возьмем переменную _LABEL_, содержащую название статистики. Для Minimum и Maximum оставим значение пустым, т.к. кол-во decimal places зависит от точности исходных данных – т.е. воспользуемся значением переменной ORIG_DP.
Код:
… invalue stat_dp 'N'=0 'Mean'=1 'Std Dev'=2 'Median'=1 'Minimum','Maximum'=.; … stat_dp=input(_label_,stat_dp.);
-
Сформируем переменную RES_DP. В ней будем хранить точность выводимой статистики в разрезе каждой из анализируемых переменных. Для этого воспользуемся функцией SUM и просуммируем значения ORIG_DP и STAT_DP. Назначим RES_DP = 0 на записях с _LABEL_ = ‘N’, т.к. N – всегда целое.
Код:
if _label_='N' then res_dp=0; else res_dp=sum(of orig_dp,stat_dp);
-
Далее вычислим ширину формата для каждой из статистик. Как вы уже знаете, числовой формат состоит из 2-х частей: ширины (w) и кол-ва decimal places (d). Записывается в виде w.d, где w – это кол-во символов, нужное чтобы сформировать результат (включая идущие впереди пробелы, целую часть, десятичную точку и дробную часть); d – кол-во знаков после запятой. Так, например, число 124.86666 имеет формат 9.5. Сохраним ширину в переменную W. По умолчанию W = DEC_POS – т.е. начальная ширина равна 10 символам, включая идущие впереди пробелы (preceding blanks) и целую часть. Для статистик, которые будут выводится с десятичной точкой нам нужно учесть также и ее, т.е. для записей, где RES_DP> 0 нужно к ширине добавить 1 (символ): W = W + 1. Ну и конечно же не забываем про дробную часть. Кол-во символов, занимающих дробную часть уже имеется в переменной RES_DP, соотв. итоговая ширина формата равна W = W + RES_DP.
Код:
w=dec_pos; if res_dp>0 then w=w+1; w=w+res_dp; -
Зная ширину формата и кол-во знаков после запятой формируем строковую переменную вида «W.D», содержащую полноценный формат для каждой переменной/статистики. Назовем ее RES_FMT. Для создания воспользуемся функцией CATX, где разделителем будет точка, первым элементом будет переменная с шириной формата W, вторым элементом – переменная с кол-вом decimal places RES_DP: RES_FMT = CATX(“.”, W, RES_DP).
Код:
res_fmt=catx(".",w,res_dp); -
В итоге создаем переменную, содержащую форматированный результат. Назовём ее RES_FORMATTED. Заранее объявим длину (чтобы всё влезло). За основу возьмем сам результат (переменная COL1). Для того, чтобы применить наш формат используем функцию PUTN – эта функция позволяет указывать формат как аргумент, что нам и нужно. Ну и чтобы результаты отстояли от краю колонки воспользуемся функцией RIGHT. В конечном итоге это выглядит так:
Код:
res_formatted=right(putn(col1,res_fmt));
С форматированием результатов закончили. Давайте посмотрим, что же получилось:
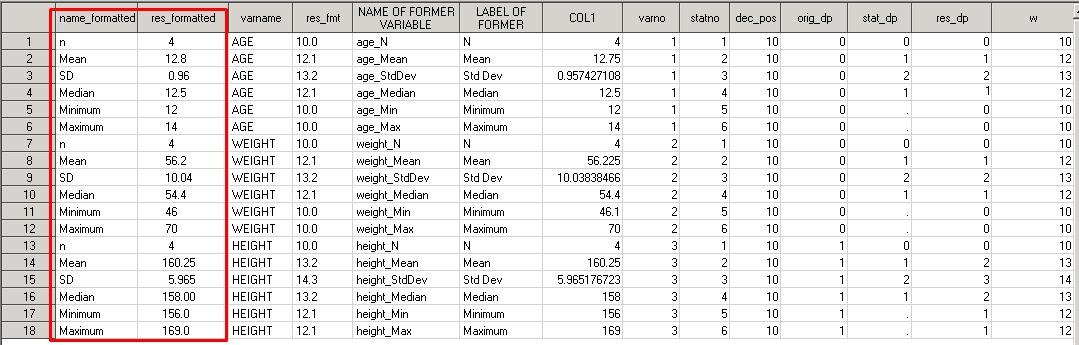
В переменных NAME_FORMATTED и RES_FORMATTED содержатся форматированные названия статистик, а также их значения по каждой переменной. Не хватает только заголовков для каждой секции (Age (years), Weight (kg) и Height (cm)) и отступов для визуального отделения заголовков от статистик. Для создания заголовков воспользуемся строковым форматом SEC_TITLE, который представит AGE как Age (years), WEIGHT как Weight (kg) и HEIGHT как Height (cm):
value $sec_title 'AGE'='Age (years)' 'WEIGHT'='Weight (kg)' 'HEIGHT'='Height (cm)';
Т.к. в нашем датасете нет строк, в которые мы могли бы записать заголовки секций (section titles) – нам их нужно искусственно создать. Для этого воспользуемся BY-group processing и оператором OUTPUT внутри DATA STEP:
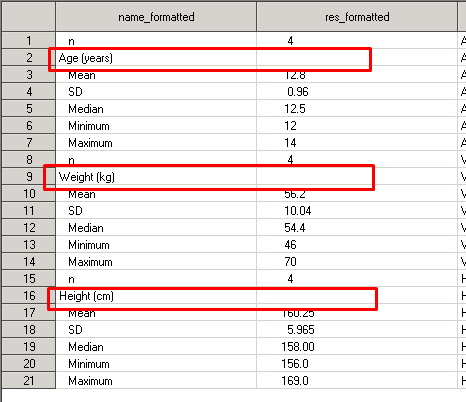
proc sort data=results_tr; by varno; run; data results_tr; set results_tr; by varno; name_formatted=repeat(" ",2)||name_formatted; output; if first.varno then do; name_formatted=put(varname,$sec_title.); res_formatted=''; section_title=1; statno=.; output; end; run;
Итак, мы выделили BY-группу. В нашем случае каждая BY-группа – это набор записей по каждой VARNO (производная от VARNAME). Первый OUTPUT выводит в датасет все уже имеющиеся в нем записи. Для того, чтобы создать отступы от левого края переменной NAME_FORMATTED применим функцию REPEAT – она повторит пробел n+1 раз (у нас это 2+1 = 3). Второй OUTPUT выполняется только при условии, что текущая запись – это первая запись из набора записей по каждой VARNO. Таким образом для каждой переменной мы получим +1 запись. На этой новой записи мы применяем PUT к VARNAME с форматом $SEC_TITLE. и записываем результат в переменную NAME_FORMATTED, отвечающую за первую колонку в отчёте. В свою очередь очищаем переменную RES_FORMATTED, т.к. новые строки – это просто заголовки, и они не имеют никаких результатов. Выставляем STATNO в пусто (для корректной сортировки внутри VARNO). Записываем в флаг SECTION_TITLE единицу. Зачем нам флаг? – спросите вы. Иметь его – это удобно при формировании отчёта – так сразу видно какие строки отвечают за заголовки, какие за результаты. Получим такой датасет:
Как видно строки появились, но не в том порядке, что нам нужно. Чтобы поменять порядок отсортируем dataset по VARNO и STATNO. Получаем конечный результат: датасет с 3 секциями и 2 колонками, в котором всё отформатировано так, как было поставлено в задаче:

Чтобы удостовериться в том, что значения статистик выровнены по десятичной точке – распечатаем переменные NAME_FORMATTED и RES_FORMATTED в Output Window с помощью PROC PRINT (подробное описание этой процедуры можно найти в следующих главах этого урока):
proc print data=results_tr; var name_formatted res_formatted; run;
Результат:
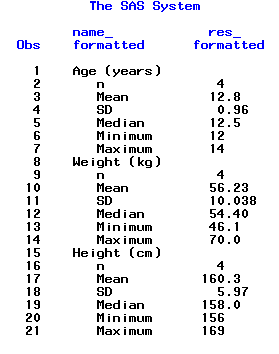
Теперь мы знаем каким образом форматировать результаты, полученные с помощью PROC MEANS. Весь код программы выгдялит так:
options nodate; proc format; invalue varno 'AGE' = 1 'WEIGHT' = 2 'HEIGHT' = 3; value $sec_title 'AGE' = 'Age (years)' 'WEIGHT' = 'Weight (kg)' 'HEIGHT' = 'Height (cm)'; invalue orig_dp 'AGE' = 0 'WEIGHT' = 1 'HEIGHT' = 0; invalue statno 'N' = 1 'Mean' = 2 'Std Dev' = 3 'Median' = 4 'Minimum' = 5 'Maximum' = 6; value $name_fmt 'N'='n' 'Std Dev'='SD' other=[$20.]; invalue stat_dp 'N' = 0 'Mean' = 1 'Std Dev' = 2 'Median' = 1 'Minimum','Maximum' = .; run; data class; infile datalines dlm='|'; length name $10 sex $1 age height weight 8; input name sex age height weight; datalines; John|M|12|159|55.7 Tony|M|12|157|53.1 Jeff|M|14|169|70.0 Anny|F|13|156|46.1 ; run; ods output summary=results; proc means data=class n mean std median min max; var age weight height; run; ods output close; proc transpose data=results out=results_tr; var age: weight: height:; run; data results_tr; length name_formatted res_formatted $50 varname res_fmt $10; set results_tr; varname=upcase(scan(_name_,1,'_')); varno=input(varname,varno.); name_formatted=put(_label_,$name_fmt.); statno=input(_label_,statno.); dec_pos=10; orig_dp=input(varname,orig_dp.); stat_dp=input(_label_,stat_dp.); if _label_='N' then res_dp=0; else res_dp=sum(of orig_dp,stat_dp); w=dec_pos; if res_dp>0 then w=w+1; w=w+res_dp; res_fmt=catx(".",w,res_dp); res_formatted=right(putn(col1,res_fmt)); run; proc sort data=results_tr; by varno; run;; data results_tr; set results_tr; by varno; name_formatted=repeat(" ",2)||name_formatted; output; if first.varno then do; name_formatted=put(varname,$sec_title.); res_formatted=''; section_title=1; statno=.; output; end; run; proc sort data=results_tr; by varno statno; run; proc print data=results_tr; var name_formatted res_formatted; run;
Дополнительные материалы: