Рассмотрим несложное, но очень важное понятие сортировки датасетов. Перед вами датасет Demo. Обратите внимание на столбец Subject Identifier for the Study (переменная SUBJID).
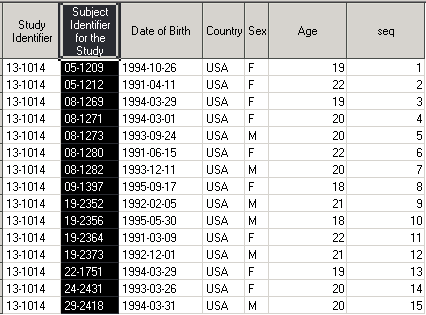
Наблюдения в датасете располагаются в порядке возрастания значений переменной SUBJID. Мы говорим, датасет Demo отсортирован по переменной SUBJID.
Отсортируем датасет по переменной AGE:
proc sort data = Demo out = dm_by_AGE; by AGE; run;
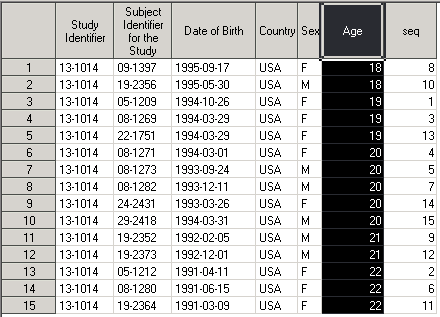
Обратите внимание на результат работы этой процедуры: создался новый датасет dm_by_AGE, который отсортирован по переменной AGE. Переменная seq показывает, как изменился порядок строк в датасете dm_by_AGE по сравнению с Demo.
Датасеты можно сортировать, как по числовым, так и по строковым переменным. Если это числовая переменная – соблюдается порядок возрастания/убывания, если это строковая переменная – соблюдается алфавитный порядок/обратный алфавитный порядок.
Чтобы отсортировать датасет в обратном порядке, нужно использовать опцию descending.
proc sort data = dm_by_AGE; by descending AGE; run;
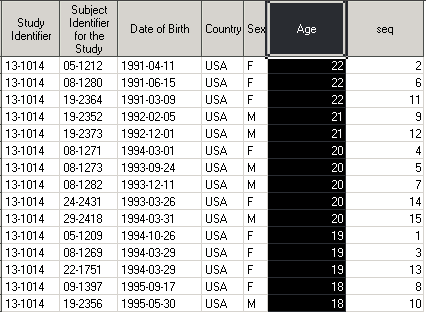
Как видите, можно не указывать опцию out, датасет dm_by_AGE теперь отсортирован по убыванию переменной AGE.
By-группа (подгруппа)
Обратите внимание, что некоторые значения переменной AGE повторяются в нескольких наблюдениях подряд. Каждая группа наблюдений с одним и тем же значением by-переменной называется by-группой. Одно значение переменной AGE – одна by-группа
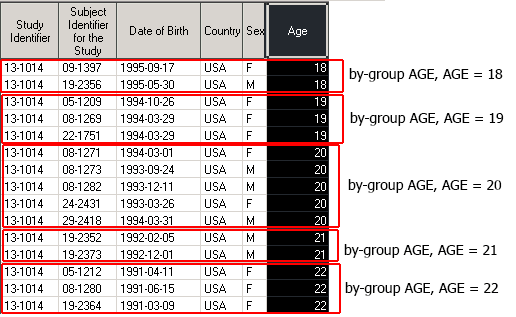
На практике нам зачастую необходимо контролировать порядок наблюдений внутри каждой by-группы. Это можно сделать, задав дополнительную by-переменную.
Пусть мы хотим, чтоб каждая by-группа AGE была отсортирована по дате рождения (BRTHDTC).
proc sort data = Demo out = dm_by_AGE_BRTHDTC; by AGE BRTHDTC; run;
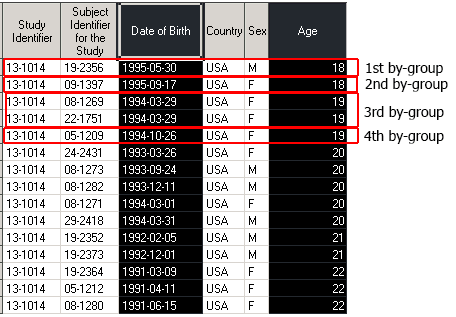
- 1st by-group: AGE = 18, BRTHDTC = 1995-05-30
- 2nd by-group: AGE = 18, BRTHDTC = 1995-09-17
- 3rd by-group: AGE = 19, BRTHDTC = 1994-03-29
- 4th by-group: AGE = 19, BRTHDTC = 1994-10-26
- etc…
Важно понимать, когда мы используем не одну by-переменную, а несколько, то by-группа – это комбинация значений всех by-переменных.
Одна уникальная комбинация – одна by-группа.
Количество by-переменных может быть более чем две, это число ограничено только количеством переменных в вашем датасете.
Также важным понятием является ключ датасета. Ключ – это такой набор by-переменных, любая by-группа которого представляет одну уникальную строку в датасете. В датасете demo ключом являться переменная SUBJID, поскольку любая by-группа SUBJID, а значит одно уникальное значение SUBJID – это одна уникальная строка в датасете. Мы говорим, в датасете demo одна строка на пациента.
Итак, сортировка датасета, by-переменные, by-группы, ключ – это понятия, с которыми мы неразлучны. Когда мы создаём стандартный датасет – он обязательно будет отсортирован в определенном порядке. Когда мы создаем таблицы и листинги – данные будут представлены в удобном порядке для просмотра (чаще всего хронологический или алфавитный, в зависимости от данных). Когда мы проводим какой-либо анализ – нам всегда может потребоваться провести его по подгруппам. Почти все наиболее часто используемые нами процедуры имеют оператор by, значит, все такие процедуры могут быть рассмотрены в контексте by-групп, и, перед использованием такой процедуры, ваш датасет должен быть предварительно отсортирован соответствующим образом.
Поверьте, многое в вашей работе будет зависеть от того, насколько правильно вы отсортируете ваш датасет.
- BY-Group Processing in the DATA Step
- SORT Procedure
На SAS support есть раздел «BY-Group Processing in the DATA Step», ознакомиться можно по ссылке:
Наиболее подробный синтаксис процедуры SORT смотрите по ссылке
Работа с by-группами на этапе дата степа
Итак, мы изучили понятие by-групп. Рассмотрим некоторые полезные операторы, связанные с обработкой by-групп.
Переменные FIRST. и LAST.
Имеется датасет Demo, отсортированный по переменной AGE и BRTHDTC:
proc sort data=Demo; by AGE BRTHDTC; run;
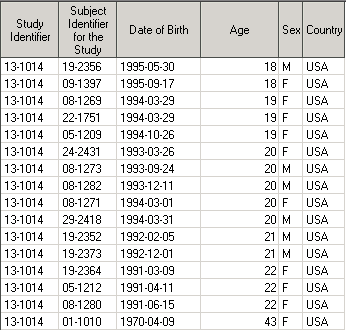
Постановка задачи: в каждой возрастной подгруппе определить самого молодого пациента. Для этого создать переменную, которая бы принимала значение ‘истина’, если пациент имеет самую позднюю дату рождения среди пациентов того же возраста, и ‘ложь’ – в противном случае. Например, в by-группе AGE = 18, таким пациентом будет 09-1397 с датой рождения 1995-09-17.
Решение: Сортировка по переменной AGE и BRTHDTC располагает строки в датасете так, что пациент с самой поздней датой рождения (т.е. самый молодой пациент) будет последним в данной возрастной подгруппе. Последнюю строку в by-группе мы всегда можем определить с помощью переменной last.<by-переменная>.
data Demo1;
set Demo;
by AGE;
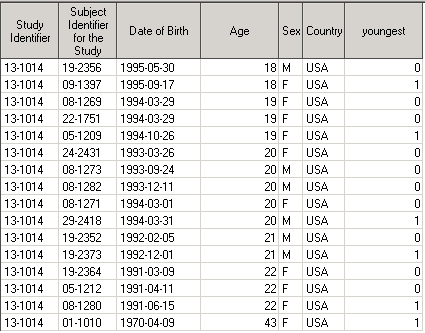
youngest = last.AGE;
run;
В результате получим датасет Demo1 c переменной youngest, которая равна 1 на последней строке в каждой by-группе AGE.
Аналогично можно определить самых старших пациентов в каждой возрастной подгруппе, воспользовавшись переменной first.<by-переменная>. На этот раз не будем создавать новую переменную, а просто выведем всех старших пациентов в датасет Demo_old, а всех младших – в датасет Demo_young.
*dataset Demo are sorted by AGE BRTHDTC; data Demo_old Demo_young; set Demo; by AGE; if first.AGE then output Demo_old; if last.AGE then output Demo_young; run;
Таким образом, мы научились определять первую и последнюю строку в by-группе.
Важно:
датасет должен быть отсортирован по переменным, указанным в by-операторе дата степа.
использование first.<by-переменная> и last.<by-переменная> не возможно без оператора by: на месте by-переменной могут стоять только переменные, указанные в by-операторе дата степа.
помним, что by-группы могут формировать несколько by-переменных. Поэтому, например, если бы мы хотели определить первую строку в каждой by-группе AGE, BRTHDTC, то дата степ выглядел бы следующим образом:
data example;
set Demo;
by AGE BRTHDTC;
if first.BRTHDTC then output example;
run;Оператор RETAIN
Как мы знаем, дата степ выполняется пошагово. За один шаг итерации обрабатывается только одна строка датасета, поэтому, в общем-то, у нас нет прямого доступа к предыдущим или последующим наблюдениям в дата степе. Тем не менее, существуют определенные инструменты, позволяющие «запоминать» значения переменных из предыдущих наблюдений. Среди таких инструментов вам уже должны быть знакомы функции lag и diff (Lesson 2.3). Здесь же мы рассмотрим оператор retain, который дает более широкие возможности.
Постановка задачи: В датасете LB хранятся результаты лабораторных тестов пациента, например это может быть анализ крови на содержание кровяных телец, уровень гемоглобина и т.д. Образцы крови для анализа берутся во время посещений (визитов) места, в котором проводят данное исследование (например, исследования могут проводиться на базе больниц). Такие визиты могут происходить несколько раз за исследование.
Рассмотрим пример датасета LB.
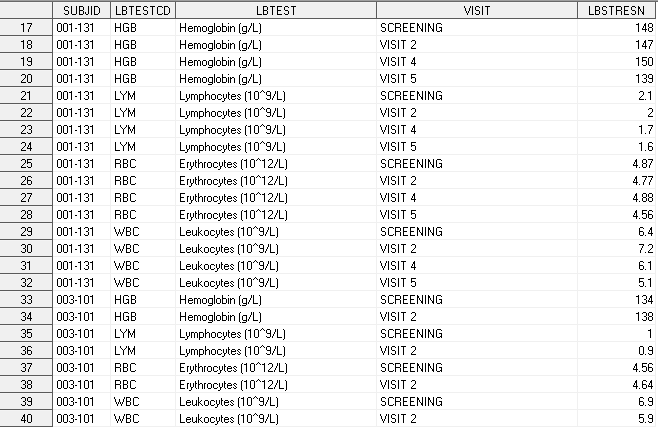
- SUBJID – номер пациента;
- LBTESTCD – кодовое название теста;
- LBTEST – полное название теста с единицами измерения;
- VISIT – название визита;
- LBSTRESN – результат теста.
В данном исследовании мы имеем один визит до приема исследуемого лекарства (VISIT=”SCREENING”) и несколько после. Вы можете заметить, что не у всех пациентов набор визитов после SCREENING одинаков. Это естественно, ведь не все пациенты проходят до конца исследования, некоторые заканчивают свое участие раньше или просто пропускают какие-то визиты в середине исследования. Итак, в датасете LB содержится одна запись на каждую уникальную комбинацию значений пациент/тест/визит. Нашей задачей будет создать переменную BASE, которая ‘запомнит’ результаты теста пациента с первого визита для всех последующих. Вот таким образом будет выглядеть итоговый датасет:
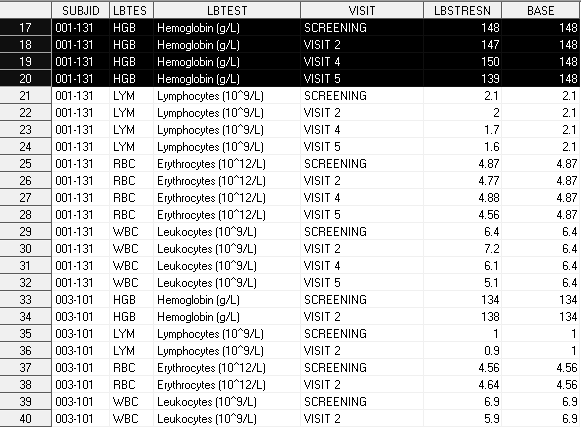
Возьмите любую by-группу пациент/тест, и вы увидите, что переменная BASE на всех визитах равна LBSTRESN с визита SCREENING. Например, уровень гемоглобина у пациента 001-131 на визите SCREENING (т.е. до приема лекарства) был 148 г/л, это значение сохранено на каждом последующем визите для того, чтобы иметь возможность сравнивать результаты до и после приема лекарства.
Решение: для решения данной задачи воспользуемся оператором retain.
proc sort data=LB; by SUBJID LBTESTCD VISIT; run; dataLB_base; set LB; by SUBJID LBTESTCD VISIT; retain BASE; if first.LBTESTCD then call missing(BASE); if VISIT = "SCREENING" then BASE = LBSTRESN; run;
Рассмотрим код пошагово.
I. Мы отсортировали датасет, зная ключ – пациент/тест/визит. Это очень важный шаг. Здесь мы располагаем строки датасета таким образом, чтобы
- подряд шли все возможные визиты для одного теста
- визиты в пределах одного теста располагались так, чтобы SCREENING всегда был первым в списке. Тут обратите особое внимание на то, что это расположение обуславливается только тем, что сортировка идет в алфавитном порядке, и для переменной VISIT имеются только значения SCREENING и VISIT X (где X = 2, 3, 4). В реальной жизни визиты могут называться по-другому, когда визит до приема лекарства по алфавиту будет стоять позже других визитов. Тогда, чтобы добиться правильной сортировки, приходится проделывать дополнительный шаг. Эту задачу мы рассмотрим на практическом занятии.
II. С помощью оператора retain мы создали переменную BASE, которая на каждой итерации дата степа будет повторять свое значение с предыдущего шага, если не задано иное. В данном случае у нас это ‘иное’ задано дважды:
- if first.LBTESTCD then call missing(BASE);. Здесь мы очищаем значение BASE на первой строке в каждой by-группе пациент/тест. Это необходимо для того, чтобы не записать результат предыдущего теста.
- if VISIT = "SCREENING" then BASE = LBSTRESN;. Здесь мы непосредственно сохраняем значение LBSTRESN с визита SCREENING. Оно будет повторяться на последующих визитах, поскольку на этих визитах мы его не переопределяем.