На прошлом уроке мы познакомились с процедурой PROC MEANS, которая используется для анализа непрерывных (continuous) данных. Для анализа категориальных (categorical) данных как правило используется PROC FREQ. Данный урок направлен на изучение базовых понятий и вариантов применения PROC FREQ.
PROC FREQ
Общий обзор
Как мы уже знаем для анализа непрерывных переменных могут быть использованы описательные статистики, такие как например среднее и стандартное отклонение. Но для категориальных переменных подсчёт среднего не имеет никакого смысла. Так какие же описательные статистики существует для категориальных переменных?
Категориальные переменные могут быть проанализированы с использованием так называемых frequency tables (таблицы частот), которые показывают количество и процент наблюдаемых событий для каждой категории анализируемой переменной. Примером категориальной переменной может служить пол (девочки, мальчики), раса (европеоидная, афроамериканская либо азиатская) и т.д.
В этом уроке мы рассмотрим, как использовать PROC FREQ для создания частотных таблиц, которые обобщают отдельные категориальные переменные.
Как и в случае с PROC MEANS, результаты, полученные после выполнения PROC FREQ, могут быть:
- Направлены в Output Window системы SAS
- Сохранены в PDF, rtf либо HTML файл средствами Output Delivery System (ODS)
- Сохранены в виде SAS датасетов, которые в дальнейшем могут быть использованы другими процедурами либо экспортированы в CSV файл
Ключевые термины и понятия
PROC FREQ также входит в базовый (BASE) модуль программной системы SAS. В рамках этой процедуры термин «анализируемая переменная» (analysis variable) подразумевает числовую (numeric) либо строковую (char) переменную (либо переменные), категориальные значения которой мы хотим проанализировать. Переменные, которые используются для группировки – «by variable(s)» (указанные в «by» statement) могут быть как числовые (numeric), так и строковые (character); значения таких переменных могут быть использованы для классификации результатов анализа «анализируемой переменной». Например, если вы хотите проанализировать строковую категориальную переменную GENDER (пол, Male vs Female) в разрезе конкретной группы учащихся (CLASSID), то «анализируемой переменной» будет GENDER, а CLASSID будет выступать в роли классификатора (by variable). Результатом выполнения PROC FREQ является frequency table, содержащая количество и процент девочек и мальчиков по каждому CLASSID. Также с помощью PROC FREQ можно получить результаты для cross-табуляции. Т.е. если у нас есть несколько категориальных переменных (например, GENDER и RACE), то мы можем посмотреть на частоты/процентные отношения между всеми уровнями этих переменных. Примеры использования cross-табуляции будут рассмотрены ниже
Также в этом уроке будут использованы такие понятия как «input data set» (входной набор данных) – исходный набор данных, наблюдения (observations) и переменные (variables) которого будут использованы при вызове PROC FREQ; и «output data set» (выходной набор данных) – SAS датасет, созданный PROC FREQ и включающий в себя результаты анализа.
Базовый синтаксис процедуры
Базовый синтаксис процедуры такой:
PROC FREQ <option(s)>; WHERE <condition>; BY <DESCENDING> variable-1 <… <DESCENDING> variable-n><NOTSORTED>; TABLES variable(s) </ option(s)>; RUN;
Давайте рассмотрим назначение каждого оператора (выделены синим выше). Итак,
- PROC FREQ: инициализирует вызов процедуры;
- WHERE: осуществляет отбор по условию (<condition>) из input data set;
- BY: создает отдельный набор статистик для каждой BY группы (переменной или набора переменных); как видно из базового синтаксиса – by-переменные могут быть представлены не только в порядке возрастания, но и нисходящем порядке, указывая ключевое слово DESCENDING перед названием by-переменой; также можно воспользоваться ключевых словом NOTSORTED после имени by-переменной, в этом случае информация будет представлена в том порядке, в котором значения by-переменной идут в input data set; при использовании by-переменных input data set должен быть предварительно по ним отсортирован;
- TABLES: указывает одну или несколько анализируемых переменных и порядок их вывода;
- RUN: выполняет ранее введенные операторы SAS.
Далее рассмотрим описание опций по каждому оператору:
| Statement | Option | Description |
|---|---|---|
| PROC FREQ | DATA = SAS-data-set | Указывает исходный набор анализируемых данных (input data set) |
| Управление выводом | ||
| NOPRINT | При указании этой опции результаты, полученные с помощью PROC FREQ, не будут отображаться в Output Window | |
| ORDER=DATA | FORMATTED | FREQ | INTERNAL |
Определяет порядок вывода категорий анализируемой переменной во frequency table согласно выбранному варианту:
|
|
| TABLES | OUT | Определяет имя output data set. |
| Управление статистическим анализом | ||
| MISSING | Учитывает пустые значения analysis переменной как непустые (валидные) | |
| Управление дополнительными возможностями | ||
| MISSPRINT | Выводит частоты для пустых значений анализируемой переменной | |
| SPARSE | Включает все возможные комбинации категорий анализируемых переменных в LIST и/или output data set | |
| LIST | Выводим результаты в описательном формате, вместо рисования таблицы | |
Вызов процедуры и описание результатов вывода
За основу возьмем input data set CLASS, содержащий информацию об учениках одного класса. Сохраним данные в input SAS data set используя DATA STEP и оператор DATALINES:
data class;
infile datalines dlm='|';
length name $10 sex $1 race $10;
input name sex race;
datalines;
John|M|White
Tony|M|Black
Jeff|M|Asian
Anny|F|White
Jane|F|White
;
run;
Выполним DATA STEP. Получим input data set вида
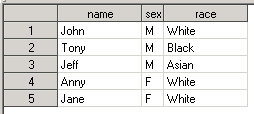
Теперь давайте посчитаем количество мальчиков и девочек в этом классе. Для этого вызовем PROC FREQ и укажем SEX как анализируемую переменную:
proc freq data = class; tables sex; run;
Результат выполнения процедуры можно посмотреть в окне Results:
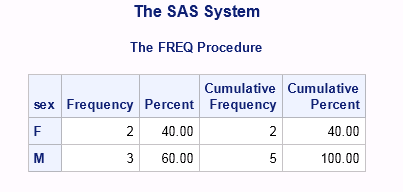
Итак, что же мы видим. В output вывелась та самая frequency table. Количество учеников каждого пола представлено колонкой Frequency (2 девочки и 3 мальчика). В колонке Percent мы видим процентное соотношение девочек и мальчиков (40 и 60% соответственно). На этом шаге давайте проверим правильность подсчёта процентов: итак из датасета мы видим, что у нас есть 2 записи для девочек, общее количество учеников равно 5, итого процент девочек составляет (2/5)*100% = 40%. Далее следует колонка «Cumulative Frequency»; из названия становится понятно, что это накопительная частота, т.е. на первой записи, где SEX = F у нас всего 2 человека, на след. записи мы к двум имеющимся прибавляем 3 оставшихс мальчиков и получаем 5 человек. Аналогичная ситуация с Cumulative Percent: 40% девочек + 60% мальчиков будет 100% всех учащихся.
Дальше давайте посчитаем количество девочек и мальчиков в разрезе расы. Для этого воспользуемся оператором BY. Как мы уже знаем input data set должен быть предварительно отсортирован по BY переменной:
proc sort data = class; by race; run; proc freq data = class; tables sex; by race; run;
В окне Results увидим следующий результат:


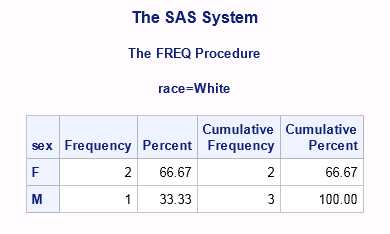
При использовании BY в окне Results мы увидим отдельный набор статистик для каждого значения BY-переменной (race = Asian, race = Black and race =White). Итак, количество мальчиков-азиатов равно 1 человеку, процентное отношение мальчиков-азиатов ко всем азиатам составляет 100% (т.е. 1 из 1). Количество мальчиков-афроамериканцев равно также 1 человеку, процентное отношение мальчиков-афроамериканцев ко всем афроамериканцам составляет 100% (т.е. 1 из 1). Количество девочек европеоидного типа равно 2 человека, что в процентном отношении ко всем людям европеоидного типа составляет 66.67%. Количество мальчиков европеоидного типа равно 1 человеку, что в процентном отношении ко всем людям европеоидного типа составляет 33.33%. Как видно из этого примера SAS посчитал проценты от количества людей в конкретной BY-группе. Сумма процентов по всем категориям analysis переменной (в нашем случае Male и Female) для каждой BY-группы сводится к 100%.
Теперь давайте проделаем все тоже самое, но с использованием cross-табуляции. Для этого нам не нужно указывать ничего, кроме TABLES. Синтаксис cross-табуляции выглядит так: TABLES <variable 1> * <variable 2>. В нашем случае это TABLES SEX * RACE:
proc freq data = class; tables sex*race; run;
В окне Results получим такую таблицу:
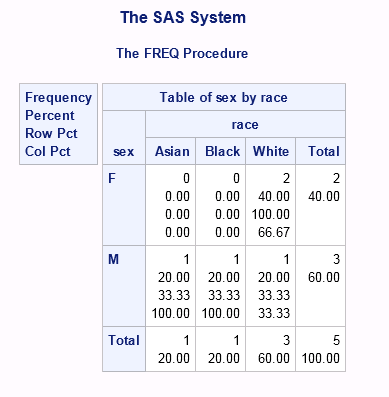
Давайте сравним полученные значения с результатами из предыдущего примера. Во-первых, мы видим намного больше информации. Куча каких-то процентов, столбцов и строк. Стоит разобраться что же это всё значит. Итак,
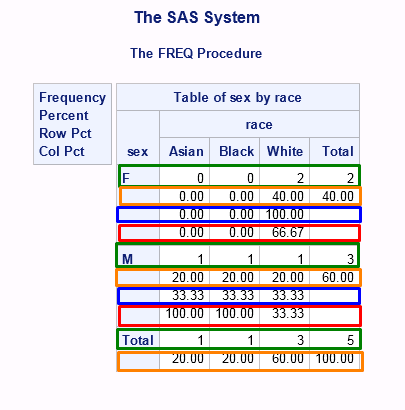
- в квадрате с аннотацией мы видим, что первой строкой в таблице идет Frequency. Строки с frequency counts выделены зеленым цветом. Значения frequency counts остались такими же (по одному мальчику каждой расы и 2 европеоидные девочки). В отличии от предыдущего примера в output также представлены нулевые частоты (zero counts). Мы конечно же видели из датасета CLASS, что в классе вообще не было азиаток и афроамериканок, но тем не менее используя оператор BY SAS не вывел эту информацию.
- вторая строка, проаннотированная как Percent (выделенная оранжевым), содержит процентное отношение количества человек конкретного пола и расы к общему количеству людей в классе, т.е. 2 европеоидные девочки составляют 40% всего класса, состоящего из 5 человек. Следует отметить, что нулевые проценты также выводятся при использовании cross-табуляции.
- третья строка, проаннотированная как Row Pct (выделенная синим), содержит процентное отношение количества человек данной расы к количеству человек данного пола, т.е. 1 мальчик-азиат составляет 33.33% от всех мальчиков класса (коих 3 человека); 2 европеоидные девочки составляют 100% от всех девочек класса (коих 2 человека).
- четвертая строка, проаннотированная как Col Pct (выделенная красным), содержит процентное отношение количества человек данного пола к количеству человек данной расы, т.е. 2 европеоидные девочки составляют 66.67% от всех людей европеоидной расы (коих 3 человека); 1 мальчик-азиат составляет 100% от всех азиатов (коих 1 человек);
- строки Total содержат общее количество (Asian = 1, Black = 1 and White = 3) и процент (Asian = 20%, Black = 20% and White = 60%) людей для каждой из рас по отношению к общему количеству человек в классе;
- столбец Total содержит общее количество (M = 3 and F = 2) и процент (M = 60% and F = 40%) людей для каждого пола по отношению к общему количеству человек в классе; - на пересечении строки Total и столбца Total можно увидеть то самое общее количество учеников, которое и составляет 100%.
Сохранение результатов
Как говорилось ранее, результаты выполнения PROC FREQ можно сохранить либо в output SAS data set, либо сразу в файл, либо и то и другое одновременно
Давайте сохраним наши результаты в output SAS data set и назовем его RESULTS. Для этого воспользуемся опцией OUT = <output data set> в операторе TABLES:
proc freq data = class; tables sex/out = results; run;
После выполнения процедуры в папке Work мы увидим датасет RESULTS, состоящий из 2 наблюдений (observations) и 3 переменных (variables):
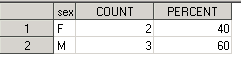
где:
- SEX – хранит все встретившиеся значения (уровни) анализируемой переменной;
- COUNT – переменная, в которой хранится общее количество записей по каждому из уровней анализируемой переменной;
- PERCENT – переменная, в которой хранится процентное отношение общего количества записей по каждому из уровней анализируемой переменной (COUNT) к общему количеству записей по всем уровням анализируемой переменной;
Т.е. в датасете RESULTS представлена всё та же информация, что и в окне Results.
Давайте попробуем сохранить результаты PROC FREQ, но уже с использование разбиения по расе с помощью оператора BY:
proc sort data = class; by race; run; proc freq data = class; tables sex/out = results_by_race; by race; run;
В папке Work появился датасет RESULTS_BY_RACE. В нем 4 observations и 4 переменных:
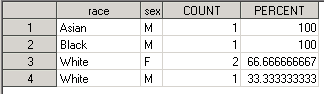
Как видим, добавилась еще одна переменная RACE. Для каждого значения RACE посчитаны COUNT и PERCENT по каждому полу.
Теперь давайте рассмотрим, как будет выглядеть output data set для cross-табуляции:
proc freq data = class; tables race*sex/out = results_by_race;; run;
Output data set имеет вид:
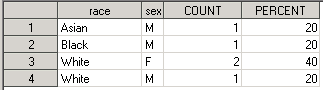
Мы увидим всё те же 4 записи и 4 переменные, но как вы можете заметить, переменная PERCENT принимает другие значения – а именно проценты были посчитаны на основе общего количества записей в input data set. Если посмотрим на окно Results – то увидим, что там представлено намного больше информации, чем у нас в датасете. Сохранить всю имеющуюся статистику можно с помощью использования ODS OUTPUT. Результаты cross-табуляции из PROC FREQ хранятся в автоматическом датасете с одноименным названием CrossTabFreqs. В этом варианте сохранения нам не нужна опция OUT, а сам синтаксис выглядит так:
ods output CrossTabFreqs=results_by_race; proc freq data = class; tables race*sex; run; ods output close;
Инструкция ODS OUTPUT открывает нам возможность манипулировать результатами вывода, а CrossTabFreqs = RESULTS_BY_RACE позволяет нам сохранить результаты выполнения процедуры в датасет в том виде, в котором они будут выведены в окне Output. В свою очередь инструкция ODS OUTPUT CLOSE закрывает направление вывода.
После выполнения вышеприведенного кода мы получим датасет RESULTS_BY_RACE, который выглядит так:
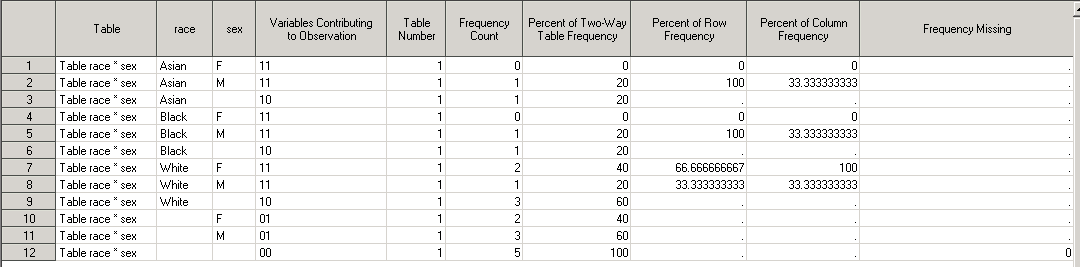
где всё именно так, как было описано выше в примере на cross-табуляцию.
Итак, мы познакомились с разными вариантами сохранения результатов в датасет. Сохранение результатов в файл аналогично тому, что было описано для PROC MEANS в прошлом уроке.
Далее рассмотрим форматирование результатов, полученных с помощью PROC FREQ.
Форматирование (formatting) результатов
Итак, за основу возьмём датасет CLASS. Для создания полноценного отчёта нам нужно посчитать n и % для таких переменных как пол (SEX) и раса (RACE) среди всех учащихся. Окончательный результат должен иметь вид:

Что же мы видим:
- конечный отчёт должен иметь 2 колонки (Characteristic и CLASS A) и 2 секции (Gender и Race). Соответственно нам нужно подготовить data set, содержащий как минимум 2 переменные и 7 записей (3 для Gender и 4 для Race);
- заголовки секций в колонке Characteristic (section titles), такие как ‘Gender, n (%)’ и ‘Race, n (%)’ должны быть зрительно отделены от блока со значениями переменных (Male, Female и т.д.);
- значения статистик (n и %) в колонке CLASS A должны быть выровнены друг под другом: n под n и % под % по десятичной точке.
Давайте перейдем к реализации. Для этого вызовем PROC FREQ указав SEX и RACE как анализируемые переменные. Из задания видно, что значения пола в датасете не совпадает с тем, который мы хотели бы вывести (M vs Male, F vs Female). Поэтому давайте сразу заведем соответствующий char формат SEX и будем его использовать при вызове процедуры. Далее сохраним результаты в data set RESULTS при помощи ODS OUTPUT. Возьмите себе на заметку, что при использовании ODS OUTPUT мы можем сохранить значения статистик для всех анализируемых переменных за раз. Также запомним, что автоматический датасет, который мы будем “ловить” с помощью ODS OUTPUT называется OneWayFreqs. Код имеет вид:
proc format;
value $sex
'M'='Male'
'F'='Female';
run;
ods output OneWayFreqs=results;
proc freq data = class;
format sex $sex.;
tables sex race;
run;
ods output close;
Давайте посмотрим, что у нас получилось. В датасете RESULTS содержится 5 записей и 9 переменных:

- переменная TABLE содержит название анализируемых переменных в виде «Table <var name>»;
- переменная F_SEX содержит форматированное (F) значение переменной SEX – вот там и пригодился наш формат!);
- переменная SEX содержит неформатированное значение;
- переменная F_RACE содержит форматированное (F) значение переменной RACE;
- переменная RACE содержит неформатированное значение – в нашем случае F_RACE = RACE, т.к. раса в датасете уже представлена в таком виде, в котором мы будем ее выводить;
- переменная FREQUENCY содержит значения частот (n) по каждому уровню каждой analysis переменной; т.е. 2 девочки, 3 мальчика; 1 азиат, 2 афроамериканца и 3 человека европеоидной расы. Это первая часть составной статистики «n (%)», которую мы будем выводить в отчет;
- переменная PERCENT содержит процентное отношение по каждому уровню каждой analysis переменной к общему количеству детей в классе. Это вторая часть составной статистики «n (%)», которую мы будем выводить в отчет;
- переменные CumFrequency и CumPercent содержат кумулятивную частоту и процент по каждой analysis переменной.
Данные готовы к форматированию. Следующим шагом давайте чётко выделим какие записи в какой переменной относятся. Сделаем это через DATA STEP след. образом: за основу возьмем переменную TABLE и отсканируем второе слово после встреченного пробела, сохраним это значение в переменную VARNAME в верхнем регистре (при помощи функции UPCASE):
data results;
length varname $10;
set results;
varname=upcase(scan(table,2,' '));
run;
Для корректной сортировки при формировании отчёта введем переменную VARNO, сформируем ее с помощью информата (INFORMAT) и функции INPUT, основываясь на уже готовое значение переменной VARNAME:
proc format;
invalue varno
'SEX'=1
'RACE'=2;
run;
data results;
length varname $10;
set results;
varname=upcase(scan(table,2,' '));
varno=input(varname,varno.);
run;
Получим датасет с 2-мя новыми переменными VARNAME и VARNO:

Далее сформируем переменную NAME_FORMATTED, в которой будут храниться форматированные значения переменных и заголовки секций. Для этого за основу возьмем переменные F_SEX и F_RACE и применим функцию COALESCEC. Функция COALESCEC возвращает первое непустое значение своих аргументов:
data results;
length varname $10 name_formatted $50;
set results;
varname=upcase(scan(table,2,' '));
varno=input(varname,varno.);
name_formatted=coalescec(of f_sex,f_race);
run;
Как и в случае с числовым представлением переменной VARNAME (а именно VARNO) нам будет удобно хранить порядковый номер значения analysis variables в переменной SEXN (sex numeric) и RACEN (race numeric). Для этого создадим 2 числовых информата: SEX и RACE и воспользуемся функцией INPUT. За основу возьмем переменные SEX и RACE соответственно:
proc format;
invalue sex
'M'=1
'F'=2;
invalue race
'White'=1
'Black'=2
'Asian'=3;
run;
data results;
length varname $10 name_formatted $50;
set results;
varname=upcase(scan(table,2,' '));
varno=input(varname,varno.);
name_formatted=coalescec(of f_sex,f_race);
sexn=input(sex,sex.);
racen=input(race,race.);
run;
Результирующий датасет пополнится еще 2-мя переменными:

Итак, мы подошли к форматированию результатов (переменные FREQUENCY и PERCENT). Стоит запомнить, что проценты как правило выводят с одним знаком после запятой – нам нужно будет это учесть при форматировании. Как было сказано выше, результирующая переменная должна состоять из двух частей – числителя (количества учащихся n) и процентного отношения (xx.x%), поэтому и форматирование делится на 2 этапа:
-
Давайте определимся какое количество символов будет выделено под вывод числителя n. Пускай это будет 10 символов (чем больше это число, тем правее от края колонки будут выведены наши результаты). Введем строковую переменную CNT (count). Сформировать ее нужно таким образом, чтобы результаты в каждой строке были выровнены по разряду числа, т.е.
.........x
........xx
.......xxxДля этого будем использовать функцию PUT и ее возможности. За основу возьмем переменную FREQUENCY, PUT-ем ее по формату 10. (именно эту ширину мы выбрали в предыдущем шаге) и выровняем результат вправо.
Код:
cnt=put(frequency, 10. -r);
-
Далее сформируем вторую часть вида «(xx.x%)». Введем переменную PCT (percent). Создадим ее на основе переменной PERCENT воспользовавшись функциями PUT и CATS (concatenation of stipped agruments). Помним, что проценты нужно вывести с одним знаком после запятой. Максимальное допустимое число для процентов в нашем примере это 100%, поэтому нам подойдет числовой формат 5.1. После применения формата заключим полученный результат в скобки и допишем знак процента.
Код:
pct=cats("(",put(percent,5.1),"%)");
-
В итоге у нас есть 2 составляющие. Осталось их правильно соединить. Конечный результат запишем в переменную RES_FORMATTED. Для этого объединим переменные CNT и PCT таким образом, чтобы ушли лишние конечные пробелы в переменной CNT, а значения PCT были выровнены по десятичной точке. Чтобы убрать лишние конечные пробелы из CNT применим функцию TRIM. Чтобы выровнять значения PCT применим PUT по char формату с корректным значением ширины этого формата. В нашем случае корректной шириной является 8 символов (т.е. открывающая скобка, 5 возможных цифр процента (учитывая десятичную точку), закрывающая скобка и знак процента). Применяя PUT не забываем выравнивать результаты вправо – так мы добьемся эффекта выравнивания по точке. И в конечном итоге соединяем 2 части с помощью оператора || через пробел.
Код:
res_formatted=trim(cnt)||" "||put(pct,$8. -r);
Выполнив все вышеприведённые шаги получим датасет вида:

В переменных NAME_FORMATTED и RES_FORMATTED содержатся форматированные названия категорий, а также их частоты по каждой переменной. Не хватает только заголовков для каждой секции («Gender, n (%)» и «Race, n (%)») и отступов для визуального отделения заголовков от категорий. Для создания заголовков воспользуемся строковым форматом SEC_TITLE, который представит SEX как «Gender, n (%)» и RACE как «Race, n (%)»:
value $sec_title 'SEX'='Gender, n (%)' 'RACE'='Race, n (%)';
Т.к. в нашем датасете нет строк, в которые мы могли бы записать заголовки секций (section titles) – нам их нужно искусственно создать. Для этого воспользуемся BY-group processing и оператором OUTPUT внутри DATA STEP:
proc sort data = results; by varno; run; data results; set results; by varno; name_formatted=repeat(" ",2)||name_formatted; output; if first.varno then do; name_formatted=put(varname,$sec_title.); res_formatted=''; section_title=1; sexn=.; racen=.; output; end; run;
Итак, мы выделили BY-группу. В нашем случае каждая BY-группа – это набор записей по каждой VARNO (производная от VARNAME). Первый OUTPUT выводит в датасет все уже имеющиеся в нем записи. Для того, чтобы создать отступы от левого края переменной NAME_FORMATTED применим функцию REPEAT – она повторит пробел n+1 раз (у нас это 2+1 = 3). Второй OUTPUT выполняется только при условии, что текущая запись – это первая запись из набора записей по каждой VARNO. Таким образом для каждой переменной мы получим +1 запись. На этой новой записи мы применяем PUT к VARNAME с форматом $SEC_TITLE и записываем результат в переменную NAME_FORMATTED, отвечающую за первую колонку в отчёте. В свою очередь очищаем переменную RES_FORMATTED, т.к. новые строки – это просто заголовки, и они не имеют никаких результатов. Выставляем SEXN и RACEN в пусто (для корректной сортировки внутри VARNO). Записываем в флаг SECTION_TITLE единицу. Зачем нам флаг? – спросите вы. Иметь его – это удобно при формировании отчёта – так сразу видно какие строки отвечают за заголовки, какие за результаты. Получим такой датасет:

Как видно строки появились, но не в том порядке, что нам нужно. Чтобы поменять порядок отсортируем dataset по VARNO, а внутри VARNO по числовому представлению каждой из категорий SEXN и RACEN. Получаем конечный результат: датасет с 2 секциями и 2 колонками, в котором всё отформатировано так, как было поставлено в задаче:
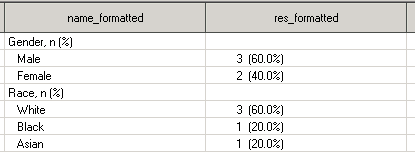
Чтобы удостовериться в том, что значения сформатированы и выровнены правильно – распечатаем переменные NAME_FORMATTED и RES_FORMATTED в Output Window с помощью PROC PRINT (подробное описание этой процедуры можно найти в следующих главах этого урока):
proc print data=results; var name_formatted res_formatted; run;
Результат:
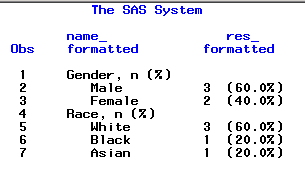
Теперь мы знаем каким образом форматировать результаты, полученные с помощью PROC FREQ. Весь код программы выгдялит так:
options nodate; proc format; value $sex 'M'='Male' 'F'='Female'; invalue varno 'SEX'=1 'RACE'=2; invalue sex 'M'=1 'F'=2; invalue race 'White'=1 'Black'=2 'Asian'=3; value $sec_title 'SEX'='Gender, n (%)' 'RACE'='Race, n (%)'; run; data class; infile datalines dlm='|'; length name $10 sex $1 race $10; input name sex race; datalines; John|M|White Tony|M|Black Jeff|M|Asian Anny|F|White Jane|F|White ; run; ods output OneWayFreqs=results; proc freq data = class; format sex $sex.; tables sex race; run; ods output close; data results; length varname $10 name_formatted res_formatted $50 cnt pct $20; set results; varname=upcase(scan(table,2,' ')); varno=input(varname,varno.); name_formatted=coalescec(of f_sex,f_race); sexn=input(sex,sex.); racen=input(race,race.); cnt=put(frequency, 10. -r); pct=cats("(",put(percent,5.1),"%)"); res_formatted=trim(cnt)||" "||put(pct,$8. -r); run; proc sort data = results; by varno; run; data results; set results; by varno; name_formatted=repeat(" ",2)||name_formatted; output; if first.varno then do; name_formatted=put(varname,$sec_title.); res_formatted=''; section_title=1; sexn=.; racen=.; output; end; run; proc sort data = results; by varno sexn racen; run; proc print data=results; var name_formatted res_formatted; run;
Дополнительные материалы: