SET statement. Вертикальное объединение датасетов.
- SET Statement
Детальная информация, касательно SET statement представлена на SAS support по ссылке
Обязательна к прочтению Chapter 10. Subsetting and Combining SAS Data Sets.
В данном уроке мы рассмотрим лишь наиболее широкое применение оператора SET и наиболее часто используемые опции при работе с ним.
Data set options
Вы уже знакомы с оператором SET: (Lesson 2.2), и знаете, что с его помощью из одного датасета можно создать другой. Например, следующий дата степ создаст датасет Demo1 на основе уже существующего датасета Demo.
data Demo1;
set Demo;
run;
Датасет, указанный после ключевого слова SET, будем называть входящим. В данном случае, оператор SET зачитает по очереди все строки и все переменные из входящего датасета Demo. На практике часто бывает нужным зачитать из входящего датасета только определенные строки и/или только определенные переменные. Рассмотрим опции, позволяющие выполнять подобные задачи.
Опция WHERE
Опция where позволяет контролировать, какие именно строки будут зачитаны из входящего датасета.
data Demo2;
set Demo(where=(SEX = 'F'));
run;
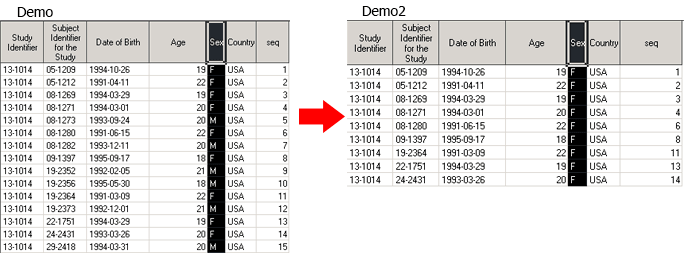
С той же целью, вместо опции where, можно использовать оператор where. Вы уже должны быть знакомы с этим оператором, по уроку 4 (Lesson 4.2). И в том, и в другом случае, переменные, которые используются в условии отбора записей, должны существовать во входящем датасете. Например, следующий код будет ошибочным, поскольку в датасете Demo нет переменной RACE
data Demo3; *Erroneous code; set Demo(where=(RACE = 'WHITE')); run;
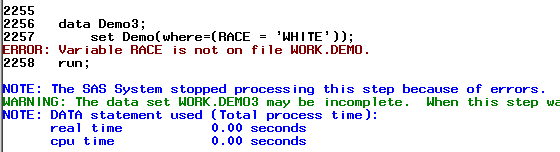
Даже если вы попытаетесь создать переменную на этапе выполнения дата степа и, с ее помощью отобрать нужные вам строки, ни оператор, ни опция where, в данном случае, вам не помогут:
data Demo3; *Erroneous code; set Demo; length sex_desc $ 10; if SEX = 'F' then sex_desc = "Female"; else if SEX = 'M' then sex_desc = "Male"; where sex_desc = "Female"; run;
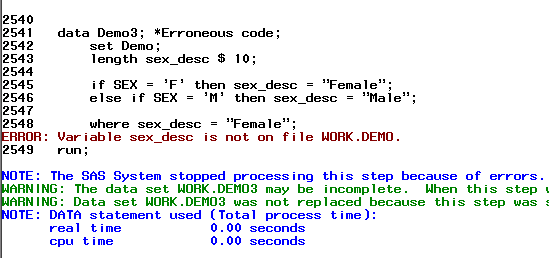
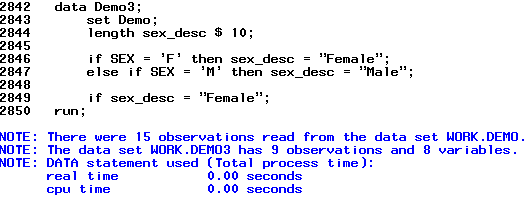
Выходом из подобной ситуации может стать использование оператора IF вместо WHERE:
data Demo3;
set Demo;
length sex_desc $ 10;
if SEX = 'F' then sex_desc = "Female";
else if SEX = 'M' then sex_desc = "Male";
if sex_desc = "Female";
run;
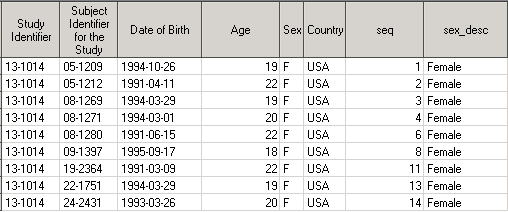
Ниже вы можете видеть лог и результирующий датасет Demo3.
Опции KEEP/DROP
Опции keep и drop позволяют контролировать, какие переменные из входящего датасета оставить (keep), а какие исключить(drop).
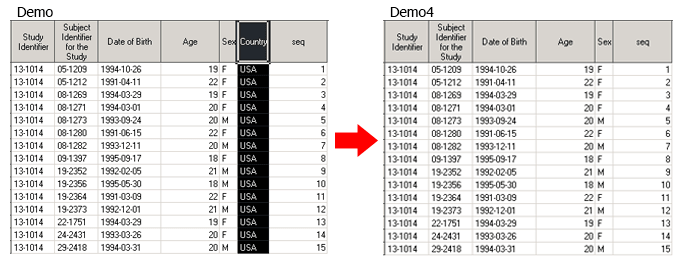
Следующий дата степ создает датасет Demo4, зачитывая все переменные, имеющиеся в Demo, кроме COUNTRY.
data Demo4; *DROP option; set Demo(drop=COUNTRY); run;
Для достижения того же результата можно использовать оператор DROP, а не опцию:
data Demo4; *DROP statement; set Demo; drop COUNTRY; run;
Существует различие между использованием опции drop и оператора drop. В случае использования опции, переменная COUNTRY будет недоступной уже на этапе выполнения дата степа. Например, следующий код будет генерировать ошибку:
data Demo4; *DROP option: erroneous code; set Demo(drop=COUNTRY where=(COUNTRY = "USA")); run;

При использовании оператора drop, переменная COUNTRY будет доступна и аналогичный код выполнится без проблем:
data Demo4; *DROP statement; set Demo(where=(COUNTRY = "USA")); drop COUNTRY; run;
Вам может показаться, что вариант с оператором, более предпочтительный, тем не менее, когда вы работаете с большими объемами данных, входящий датасет содержит большое количество переменных, и вы знаете, что некоторые из них вам не нужны, тогда использование именно опции drop будет предпочтительным, поскольку это экономит ресурсы.
Вертикальное объединение датасетов
Входящих датасетов, указанных после ключевого слова SET, может быть несколько. В этом случае, оператор SET выполняет то, что называется вертикальным объединением датасетов.
Предположим, вы получили информацию о пациентах в двух разных датасетах, в одном датасете – пациенты женского пола, во втором – мужского. Перед вами стоит задача объединить эти две группы пациентов в один датасет, следующим образом:

Рис. 14
SAS предоставляет несколько способов это реализовать, мы рассмотрим наиболее часто используемый:
data demo_all1;
set Females Males;
run;
Рассмотрим результат выполнения дата степа:
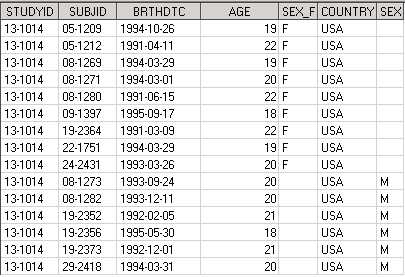
В конец датасета Females добавились строки из Males. Переменные STUDYID, SUBJID, BRTHDTC, AGE, COUNTRY, которые были как в одном, так и в другом датасете, объединились в соответствующие столбцы. Переменные SEX_F и SEX содержат одну и туже информацию – пол пациента, и логично было бы чтоб эта информация хранилась в одной переменной.
Как быть в данном случае? Ответ прост – переименовать одну из переменных.
data demo_all1;
set Females(rename = (SEX_F=SEX)) Males;
run;
Результатом этого дата степа будет датасет demo_all1 в том виде, в котором он представлен на рисунке Рис. 14.
Еще одна часто встречающаяся проблема при вертикальном объединении датасетов при помощи SET – несоответствующие типы переменных. В датасете Males2 переменная BRTHDTC (дата рождения пациента) представлена в числовом виде, с наложенным форматом date9. В датасете Females эта переменная – строковая.
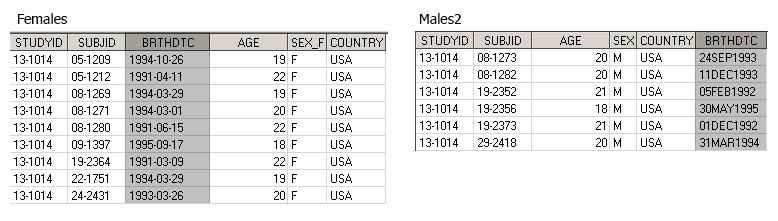
Задача: объединить датасеты Females и Males2 так, чтобы дата рождения пациентов хранилась в одной строковой переменной.
data Males2;
set Males2(rename=(BRTHDTC=BRTHDTC_old));
length BRTHDTC $ 20;
BRTHDTC = put(BRTHDTC_old, is8601da.);
drop BRTHDTC_old;
run;
data demo_all2;
set Females(rename=(SEX_F=SEX)) Males2;
run;
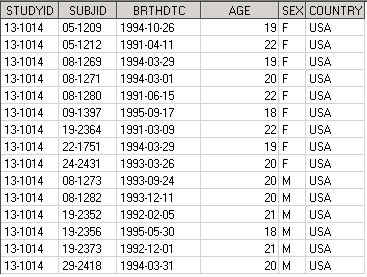
Итак, мы рассмотрели процесс, когда в конец одного датасета добавляются строки из другого датасета – так называемая, конкатенация датасетов (concatenating data sets). Добавить строки из одного датасета к другому можно и по-другому. Если все входящие датасеты будут одинаково отсортированы, то можно добавлять строки каждого из них поочередно, следуя заданной сортировке, и в итоге получить отсортированный датасет. Этот процесс называется interleaving data sets, или – упорядочивание.
proc sort data = Females out = Fem(rename=(SEX_F=SEX)); by SUBJID; run; proc sort data = Males; by SUBJID; run data demo_all3; set Fem Males; by SUBJID; run;
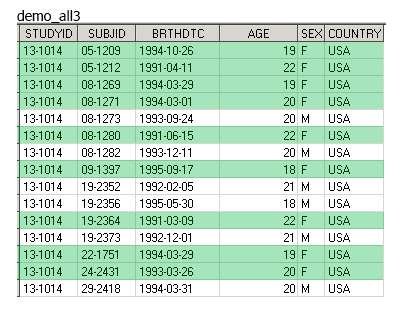
В этом случае результирующий датасет demo_all3 сразу будет отсортирован по SUBJID.
Важно:
- все входящие датасеты должны быть отсортированы по SUBJID
- оператор BY должен следовать сразу же после оператора SET
- одному оператору SET соответствует один оператор BY (потому что, вообще говоря, в дата степе может быть более одного оператора SET)
Как несложно догадаться, тот же результат можно получить, сделав set датасетов без оператора BY, а потом отсортировать получившийся датасет. Незначительная разница этих подходов состоит в том, что после применения PROC SORT для датасета устанавливается атрибут Sorted = YES, и SAS теперь не будет повторно сортировать датасет по тем же by-переменным. При объединении датасетов с оператором by атрибут Sorted остается NO, что вряд ли станет для вас проблемой.