В предыдущих уроках мы познакомились с наиболее распространёнными статистическими процедурами PROC MEANS и PROC FREQ. Сегодня мы познакомимся с процедурой PROC PRINT, которая позволит вам создать (распечатать или PRINT) простейший отчёт на основе имеющихся данных.
PROC PRINT
Общий обзор
Процедура PRINT или PROC PRINT, существует примерно с тех времен, когда вообще появился SAS. Несмотря на то, что эта процедура была частично заменена на процедуру REPORT, есть еще много случаев, когда вы можете ею воспользоваться. Процедура PRINT является одной из первоочередных вещей, которые нужно освоить начинающему программисту SAS, поскольку она обеспечивает легкий и простой способ взглянуть на записи в датасете. Также в этом уроке мы научимся сохранять вывод из PROC PRINT в простой текстовый файл или RTF файл.
Базовый синтаксис процедуры
Базовый синтаксис процедуры такой:
PROC PRINT <option(s)>; WHERE <condition>; BY <DESCENDING> variable-1 <… <DESCENDING> variable-n><NOTSORTED>; PAGEBY BY-variable; VAR variable(s); RUN;
Давайте рассмотрим назначение каждого оператора (выделены синим выше). Итак,
- PROC PRINT: инициализирует вызов процедуры; распечатывает записи из input data set;
- WHERE: осуществляет отбор по условию (<condition>) из input data set;
- BY: создает отдельную секцию отчёта для каждой BY-группы; как видно из базового синтаксиса – by-переменные могут быть представлены не только в порядке возрастания, но и нисходящем порядке, указывая ключевое слово DESCENDING перед названием by-переменой; также можно воспользоваться ключевых словом NOTSORTED после имени by-переменной, в этом случае информация будет представлена в том порядке, в котором значения by-переменной идут в input data set; при использовании by-переменных input data set должен быть предварительно по ним отсортирован;
- PAGEBY: указывает BY переменную, для каждого значения которой будет создана новая страница в отчёте; используется в конъюнкции с оператором BY, т.е. предварительно должна быть объявлена в операторе BY;
- VAR: указывает переменные, которые нужно включить в отчёт, а также порядок их вывода; если вы опустите оператор VAR, то SAS распечатает все переменные, которые есть в input data set;
- RUN: выполняет ранее введенные операторы SAS.
Далее рассмотрим описание опций по каждому оператору:
| Statement | Option | Description |
|---|---|---|
| PROC PRINT | DATA = SAS-data-set | Указывает исходный набор выводимых данных (input data set) |
| Управление общим форматом вывода | ||
| BLANKLINE = <n> | Создает пустую строку после каждых n записей в исходном датасете | |
| DOUBLE | Создает пустую строк между записями из исходного датасета | |
| N = 'string' | Печатает количество записей в исходном датасете, либо BY-группе и указывает пояснительный текст, который будет выведен вместе с количеством записей | |
| NOOBS | Позволяет не выводить колонку Obs (порядковый номер печатаемой записи) в output | |
| OBS = 'string' | Позволяет задавать заголовок колонки Obs (порядковый номер печатаемой записи) | |
| ROUND | Округляет числовые переменный (на которые не наложен формат) до 2 знаков после запятой | |
| Управление форматом страниц | ||
| WIDTH = FULL| MINIMUM| UNIFORM| UNIFORMBY |
Определяет ширину колонки для каждой выводимой переменной. Принимает такие значения:
|
|
| Управление форматом колонок (столбцов) | ||
| HEADING = HORIZONTAL (H)| VERTICAL (V) |
Задает ориентацию вывода заголовков колонок (горизонтально либо в е р т и к а л ь н о) По умолчанию HEADING = H |
|
| LABEL | Инструкция к использованию label-ов переменных в качестве заголовков колонок | |
| SPLIT = 'split-char' | Указывает split-символ, который позволит разбивать заголовки колонок на несколько строк | |
Вызов процедуры и описание результатов вывода
За основу возьмем input data set SCORES, содержащий информацию об успеваемости учеников одного класса. Сохраним данные в input SAS data set используя DATA STEP и оператор DATALINES:
data scores; infile datalines dlm='|'; length name $10 subject $20 score 8; input name subject score; datalines; John|Math |98 John|English |76 John|Biology |81 John|Physics |69 John|Economics |79 Tony|Math |65 Tony|English |34 Tony|Biology |87 Tony|Physics |56 Tony|Economics |90 Jeff|Math |41 Jeff|English |45 Jeff|Biology |56 Jeff|Physics |78 Jeff|Economics |34 ; run;
Выполним DATA STEP. Получим input data set вида:
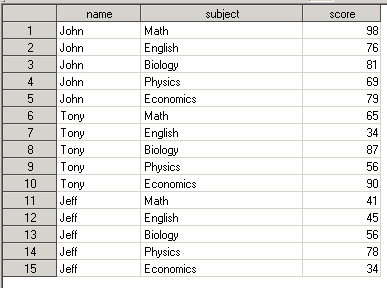
Теперь давайте выведем информацию из датасета SCORES в окно Output. Для этого вызовем PROC PRINT без опций и оператора VAR (т.е. SAS распечатает все переменные, которые имеются в датасете):
proc print data=scores;
run;
Результат выполнения процедуры можно посмотреть в окне Output:
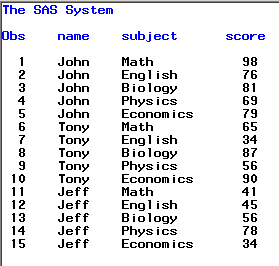
Итак, что же мы видим. В output вывелась вся информация, которая содержится в датасете SCORES, а также колонка Obs, которая указывает порядковый номер записи в output. Заголовки колонок совпадают с именами переменных.
Теперь давайте выведем всё ту же информацию, но уже с использованием оператора BY. Группировку будем производить на основе переменной SUBJECT (предмет). Помним, что при использовании BY нужно предварительно отсортировать input data set по BY переменной:
proc sort data=scores; by subject; run; proc print data=scores; by subject; run;
В итоге получим след. результат в окне Output:
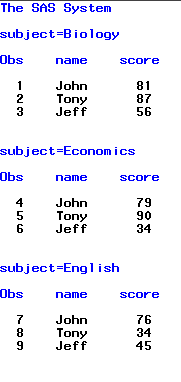

Теперь мы видим, что наши данные сгруппированы по названию предмета (SUBJECT). Колонка SUBJECT трансформировалась в название секции. Для каждого значения SUBJECT (Biology, Economics, English, Math и Physics) вывелась отдельная секция.
Далее давайте сформируем отчёт, задействовав некоторые опции, описанные выше. Итак, разбивку всё также будем делать по SUBJECT, но теперь мы хотим, чтобы данные по каждому предмету начинались с новой страницы – для этого воспользуемся оператором PAGEBY и укажем в него SUBJECT. Отделим записи по каждому студенту пустой строкой с помощью опции DOUBLE. Уберем из вывода колонку Obs с помощью опции NOOBS. Выведем количество записей по каждому предмету с помощью опции N = , указав “# of students per Subject” как описательную информацию. Воспользуемся опцией LABEL для того, чтобы перенести variables’ labels в качестве заголовков колонок (предварительно в датасете нужно задать эти labels). Ну и в конечном итоге укажем пробел как split-символ в опции SPLIT (этим мы добьёмся эффекта разбиения заголовков колонок на несколько строк в тех местах, где в label был встречен пробел).
Labels для переменных зададим так:
data scores; infile datalines dlm='|'; length name $10 subject $20 score 8; label name="Student's Name"; label subject="Subject"; label score="Subject's Score"; input name subject score; datalines; … ; run;
Далее вызовем PROC PRINT:
proc sort data=scores; by subject; run; proc print data=scores double noobs n='# of students per Subject = ' label split=' '; by subject; pageby subject; run;
Как результат получим 5 страниц информации (по одной странице на каждый предмет):
-
Страница 1

-
Страница 2

-
Страница 3

-
Страница 4

-
Страница 5
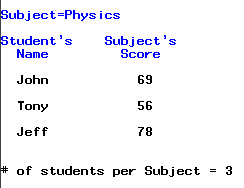
Мы научились генерировать простейшие отчёты, теперь давайте рассмотрим, как проделанную работу сохранить в файл.
Сохранение результатов
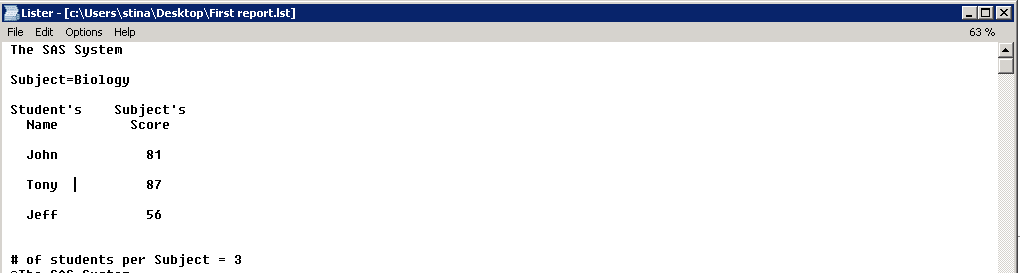
Если вам нужно сохранить результаты в обычном текстовом виде можно воспользоваться направлением ODS LISTING с опцией FILE:
ods listing file="c:\Users\stina\Desktop\First report.lst"; proc print data=scores double noobs n='# of students per Subject = ' label split=' '; by subject; pageby subject; run; ods listing close;
где FILE = “<полный путь к файлу с расширением .lst>”. В результате будет создан файл First report.lst и выглядеть он будет так:

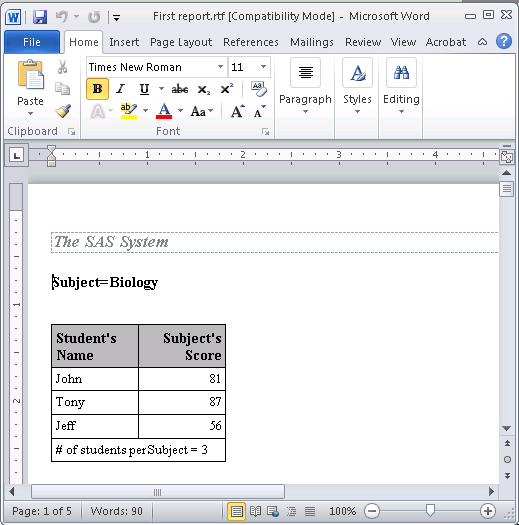
Для того, чтобы сохранить результаты в RTF файл воспользуемся направлением RTF с опцией FILE:
ods rtf file="c:\Users\stina\Desktop\First report.rtf"; proc print data=scores double noobs n='# of students per Subject = ' label split=' '; by subject; pageby subject; run; ods rtf close;
где FILE = “<полный путь к файлу с расширением .rtf>”. В результате будет создан файл First report.rtf и выглядеть он будет так:

Тоже самое можно проделать для сохранения результатов в PDF (используя ODS PDF destination) и HTML (используя ODS HTML destination).
Полный код программы с использованием PROC PRINT и сохранением отчётов в .lst и .rtf форматах:
dm log "clear"; dm odsresults "clear"; dm output "clear"; options nocenter nodate nonumber; data scores; infile datalines dlm='|'; length name $10 subject $20 score 8; label name="Student's Name"; label subject="Subject"; label score="Subject's Score"; input name subject score; datalines; John|Math |98 John|English |76 John|Biology |81 John|Physics |69 John|Economics |79 Tony|Math |65 Tony|English |34 Tony|Biology |87 Tony|Physics |56 Tony|Economics |90 Jeff|Math |41 Jeff|English |45 Jeff|Biology |56 Jeff|Physics |78 Jeff|Economics |34 ; run; proc sort data=scores; by subject; run; * Save results to .lst file; ods listing file="c:\Users\stina\Desktop\First report.lst"; proc print data=scores double noobs n='# of students per Subject = ' label split=' '; by subject; pageby subject; run; ods listing close; * Save results to .rtf file; ods rtf file="c:\Users\stina\Desktop\First report.rtf"; proc print data=scores double noobs n='# of students per Subject = ' label split=' '; by subject; pageby subject; run; ods rtf close;
Дополнительные материалы: