Merge Statement (Слияние датасетов)
Обязательна к прочтению Chapter 10. Subsetting and Combining SAS Data Sets.
В предыдущем уроке мы добавляли строки из одного датасета к другому. Существует, в некотором смысле, противоположная задача – добавление переменных из одного датасета в другой.
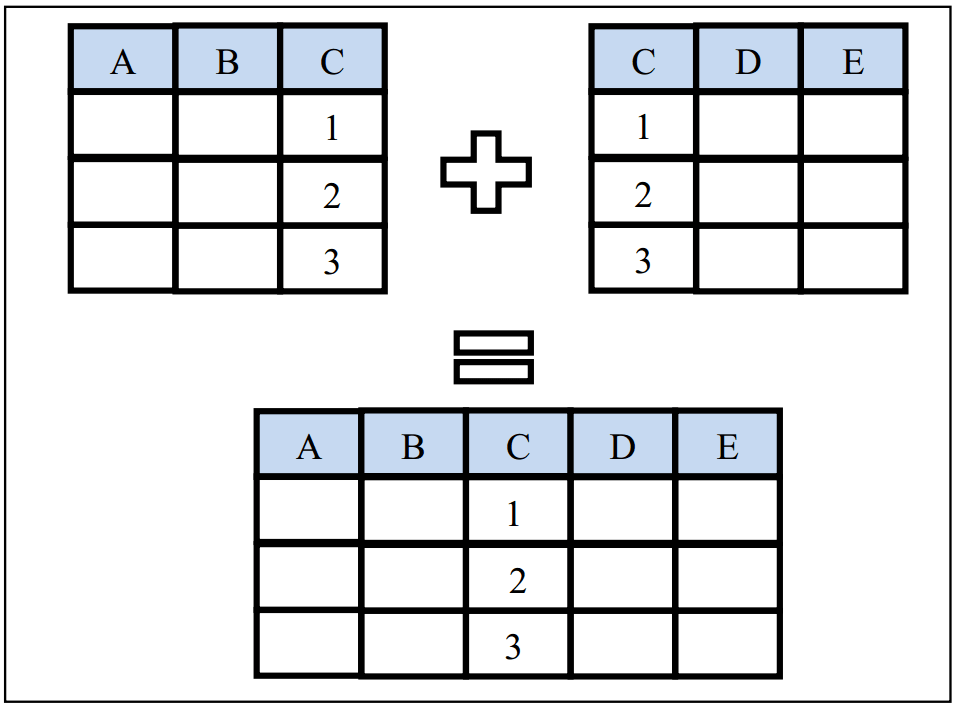
Допустим, информация о возрасте пациентов содержится в датасете Demo_age, а остальная информация (например, пол, страна) - в датасете Demog. Необходимо объединить эту информацию в один датасет Demo_all5.

proc sort data = Demog; by SUBJID; run; proc sort data = Demo_age; by SUBJID; run; data demo_all5; merge Demog Demo_age; by SUBJID; run;
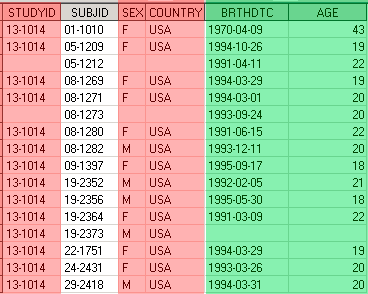
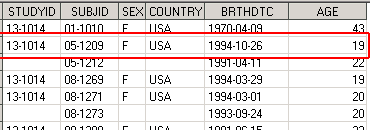
В результате выполнения этого дата степа к датасету Demog справа будут присоединены столбцы BRTHDTC и AGE. При этом, by-переменная SUBJID является своеобразным связующим звеном – ее значения определяют какие значение AGE и BRTHDTC записать в одну строку со значениями SEX, COUNTRY, STUDYID. Например, значение SUBJID = ‘05-1209’ присутствует в обоих датасетах, в датасете Demo_age для этого пациента значение AGE = 19, а в датасете Demog – значение SEX = ‘F’, это значит, что в результирующем датасете мы получим строку, где SUBJID = ‘05-1209’, AGE = 19, SEX = ‘F’.
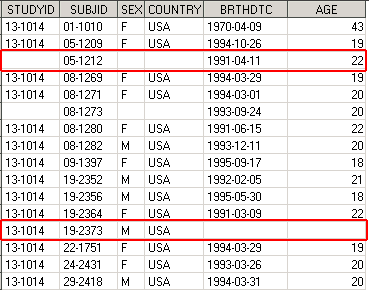
Значение SUBJID = ‘05-1212’ встретилось только в датасете Demog_age, следовательно, значения STUDYID, SEX, COUNTRY в этой строке будут пустыми. И наоборот, в случае, когда значения SUBJID “19-2373” не нашлось в датасете Demog_age, пустыми будут значения AGE и BRTHDTC.
Опция IN
Часто бывает нужным оставить в результирующем датасете только те наблюдения, в которых значения by-переменных встретились во всех входящих датасетах. Или же, наоборот, узнать какие значения by-переменной встретились только в одном из датасетов.
Это возможно с помощью опции IN.
Опцию IN можно также использовать для SET Statement, для того, чтобы определить с какого из входящих датасетов пришли те или иные строки при вертикальном объединении датасетов. Рассмотрим пример для наглядности:
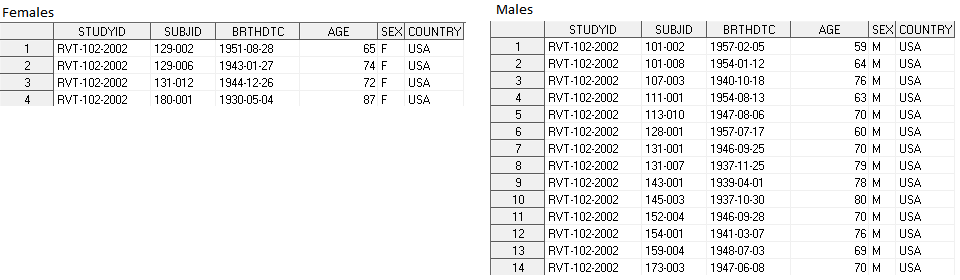
Объеденим датасеты Females и Males следующим образом:
data All_sex;
set Females(in=in1)
Males(in=in2);
Females=in1;
Males=in2;
run;
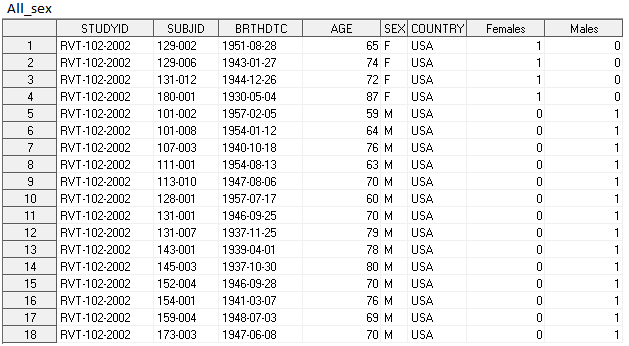
В результате получили dataset All_sex, в котором переменные Females и Males показывают с какого входящего датасета пришли строки.
Но, это было отступление, давайте все же вернемся к Merge Statement и подробнее разберем эту опцию. Для этого рассмотрим следующий код:
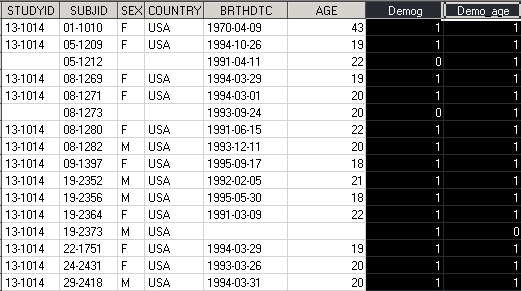
*Demo_age and Demog datasets are sorted by SUBJID; data demo_all6; merge Demog(in=in1) Demo_age(in=in2); by SUBJID; Demog = in1; Demo_age = in2; run;
Шаг 1. Опция in для датасета Demog создает временную переменную in1, которая равна 1(истина), если строка присутствует в Demog, и 0(ложь) – если нет. Аналогично, для датасета Demo_age, создана временная переменная in2: in2 = 1, если строка присутствует в Demo_age, in2 = 0 – если нет. Переменные Demog и Demo_age созданы для демонстрации значений временных переменных in1 и in2.
Шаг 2. Воспользуемся временными переменными in1 и in2 для отбора нужных записей.
data demo_all7;
merge Demog(in=in1)
Demo_age(in=in2);
by SUBJID;
if in1 and in2;
run;
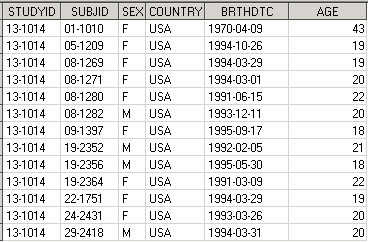
В результате применения оператора IF в датасете demo_all7 окажутся только те записи, где in1 = 1 и in2 = 1, то есть только те записи, которые присутствовали в обоих входящих датасетах.
Таким образом, контролировать какие строки останутся в результирующем датасете можно, задав подходящее условие в IF оператор. Например, если в предыдущем примере заменить IF оператор на такой: if in1;, то останутся только те строки, которые были в датасете Demog.
Попробуем узнать теперь, у кого из пациентов есть информация только о возрасте, но нет о поле.
*Demo_age and Demog datasets are sorted by SUBJID; data demo_age_only; merge Demog(in=in1) Demo_age(in=in2); by SUBJID; if not in1 and in2; run;

By-переменная при merge должна обязательно называться одинаково во всех входящих датасетах, и быть одного типа. Естественно в реальном мире, это не всегда оказывается так, и приходится проделывать дополнительные шаги. Как сделать merge датасетов по пациентам, если в одном из них номер пациента – это переменная SUBJID, а во втором – PT? Ответ вам должен быть уже известен – переименовать одну из переменных. Как сделать merge датасетов по пациентам, если в одном из них переменная с номером пациента – числовая, а во втором – строковая? Ответ очевиден – создать в одном из датасетов новую переменную, которая будет соответствовать типу аналогичной переменной во втором датасете.
Рассмотрим такую задачу на примере. Датасет subj содержит информацию о пациентах (дата рождения, пол, возраст, страна), в нем переменная SUBJID (номер пациента) - строковая. Датасет TRT содержит информацию о лечении пациентов: он содержит числовую переменную SUBJID (номер пациента) и строковую переменную TRT (равна “PLACEBO” или “ TEST ”, в зависимости от того, принимал ли пациент плацебо, или тестируемое лекарство). Задача: создать датасет, в котором для каждого пациента была бы вся информация из обоих датасетов.
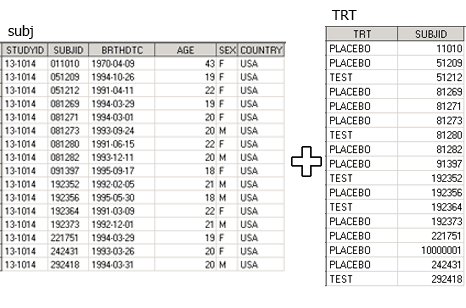
proc sort data = subj; by SUBJID; run; data TRT; set TRT(rename=(SUBJID=PT)); length SUBJID $ 10; SUBJID = put(PT, best.-l); if lengthn(SUBJID) = 5 then SUBJID = "0" || SUBJID; drop PT; run; proc sort data = TRT; by SUBJID; run; data demo_all8; merge subj TRT; by SUBJID; run;

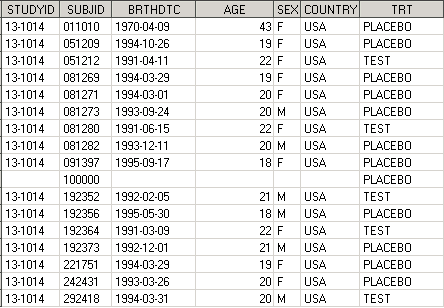
Обратите внимание на лог программы. SAS предупреждает, что длина by-переменной во входящих датасетах разная, что может привести к непредвиденным последствиям. Это последствие мы можем наблюдать на пациенте с необычным номером, более длинным, чем у всех остальных, в датасете TRT он был “10000001”, а в результирующем demo_all8 стал “100000”, поскольку, длина переменной SUBJID в датасете subj была равна 6. Длина by-переменной будет такой, как в первом из перечисленных датасетов после ключевого слова merge. Выходов из данной ситуации может быть несколько.
-
Переопределить длину переменной SUBJID в датасете subj:
data subj; length SUBJID $ 10; set subj; run; proc sort data = subj; by SUBJID; run; data TRT; set TRT(rename=(SUBJID=PT)); length SUBJID $ 10; SUBJID = put(PT, best.-l); if lengthn(SUBJID) = 5 then SUBJID = "0" || SUBJID; drop PT; run; proc sort data = TRT; by SUBJID; run; data demo_all8; merge subj TRT; by SUBJID; run;Обратите внимание на первый дата степ. Поскольку SUBJID уже существует во входящем датасете subj, то определение ее длины должно следовать до оператора SET. В противном случае, выполнение дата степа начнется с оператора SET, и переопределение длины любой переменной входящего датасета будет невозможным. В случае же когда мы сначала задаем длину SUBJID, создается новая переменная SUBJID, и уже на ее место будут записываться значения из “старой” переменной входящего датасета.
-
Задать длину SUBJID в том же дата степе, в котором выполняется merge:
data TRT; set TRT(rename=(SUBJID=PT)); length SUBJID $ 10; SUBJID = put(PT, best.-l); if lengthn(SUBJID) = 5 then SUBJID = "0" || SUBJID; drop PT; run; proc sort data = TRT; by SUBJID; run; data demo_all8; length SUBJID $ 10; merge subj TRT; by SUBJID; run; -
Поменять местами входящие датасеты subj и TRT при merge:
proc sort data = subj; by SUBJID; run; data TRT; set TRT(rename=(SUBJID=PT)); length SUBJID $ 10; SUBJID = put(PT, best.-l); if lengthn(SUBJID) = 5 then SUBJID = "0" || SUBJID; drop PT; run; proc sort data = TRT; by SUBJID; run; data demo_all8; merge TRT subj; by SUBJID; run;
Третий вариант сработает именно потому, что теперь первым указывается TRT датасет, в котором длинна by-переменной больше, чем в subj (а, как мы помним, в результирующем датасете длинна by-переменной устанавливается такой, как в первом из перечисленных датасетов).
One-to-Many Merge (Слияние один ко многим)
Рассмотрим понятие ключа в датасете. Ключ – это такой набор by-переменных, любая by-группа которого является уникальной строкой в датасете.
Во всех предыдущих примерах, в обоих входящих датасетах, by-переменная SUBJID являлась ключом, поскольку все значения переменной SUBJID были уникальными (другими словами, любое значение переменной SUBJID встречалось в одной, и только в одной строке датасета).
Такое слияние датасетов называется один к одному.
Можно так же рассматривать понятие слияния один ко многим. В этом случае, в одном из входящем датасете, но не более, чем в одном, by-переменные не являются ключом.
Рассмотрим пример. Датасет Adverse содержит информацию о том, какие нежелательные явления (adverse events) происходили с пациентом на протяжении исследования. Это могли быть болезни, травмы, реакции, и т.п. Понятно, что у каждого пациента могло возникнуть несколько таких явлений, и поэтому в датасете Adverse может быть несколько записей для одного и того же пациента. С датасетом TRT вы уже знакомы, там находятся те же пациенты, что и в Adverse, но в датасете TRT каждое значение SUBJID задает уникальную строку. Наша задача, добавить в датасет Adverse информацию о лечении пациента из датасета TRT.
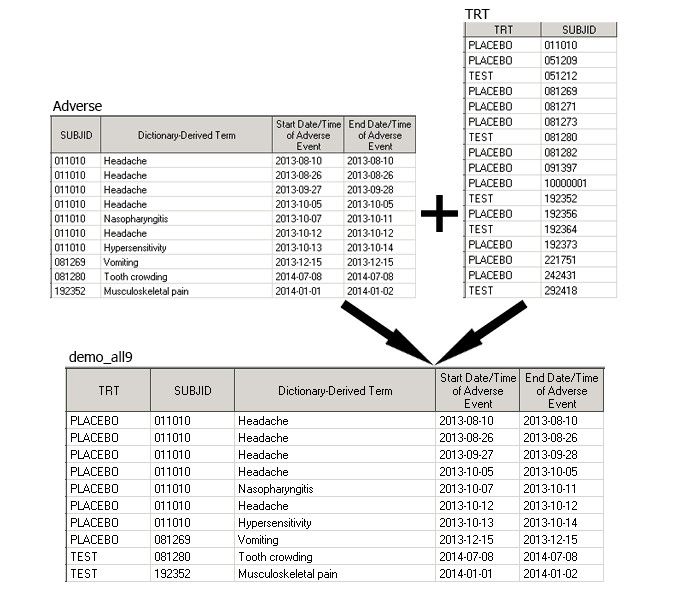
proc sort data = Adverse; by SUBJID; run; *dataset TRT has already been sorted; data demo_all9; merge TRT Adverse(in=inae); by SUBJID; if inae; run;
В результате получим нужный нам датасет. Снова обратите внимание на использование опции IN, с ее помощью мы избавились от пациентов, у которых не случилось ни одного нежелательного явления (то есть те, которых не было в датасете Adverse, но были в датасете TRT).
Ccылка на merge statement sas-support: