В этом занятии ознакомимся с еще одной важной процедурой в языке SAS – PROC SQL, с помощью которой можно преобразовывать набор данных, суммировать данные, сортировать и группировать данные, объединять несколько дата сетов, делать отчеты и создавать макро переменные.
Объявляется процедура с помощью ключевого PROC SQL; . Заметим, что после названия процедуры мы не указываем какой дате сет будет использоваться дальше. Также в отличие от всех ранее изучаемых процедур, для выхода из PROC SQL нужно указать оператор QUIT;.
Рассмотрим примеры использования proc SQL на дата сете demo:
Самый простой и часто используемый оператор в PROC SQL – SELECT.
Команда SELECT
- выбирает данные, которые удовлетворяют определенным условиям
- группирует данные
- определяет порядок данных
- форматирует данные
Синтаксис оператора:
SELECT column-1 <, column -2>… FROM table-1|view-1<,table-2|view-2>… <WHERE statement> <GROUP BY column-1 <,column -2>…> <ORDER BY column-1 <,column -2>…<DESC>>;
- SELECT - задает необходимые колонки
- FROM - указывает запрашиваемую таблицу.
- WHERE - подставляет данные, удовлетворяющие условию.
- GROUP BY - сортирует данные по группам.
- ORDER BY - сортирует строки по значениям указанных столбцов. По умолчанию, результат сортируется в порядке возрастания. Используйте ключевое слово DESC для сортировки в убывающем порядке.
Обратите внимание на то, что в PROC SQL все переменные разделяются запятой и точка с запятой ставится только в конце команды SELECT
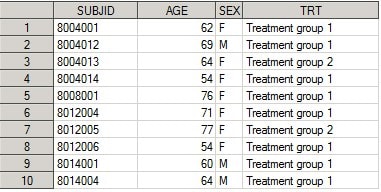
Для примера, отберем переменные с номером пациента, его полом и возрастом из дата сета demo:
proc sql;
select SUBJID, SEX, AGE
from demo;
quit;
|
|
|
В результате получаем отчет в окне Results Viewer :
Для того, чтобы сохранить эту таблицу в файл формата .lst или .rtf, надо воспользоваться ods listing file или же ods rtf file (см. урок 6.4). |
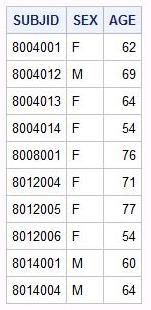
Для того, чтобы выбрать ВСЕ переменные из исходного дата сета, используем символ * (звездочка) :
proc sql;
select *
from demo;
quit;
|
|
| Результатом будет таблица, в которой столбцы в том порядке, в котором переменные дата сета demo |
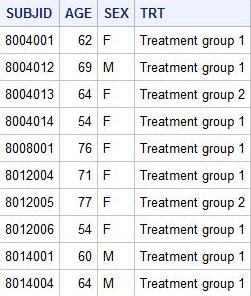
По умолчанию PROC SQL выдает все строки таблицы.
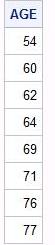
| Для того, чтобы устранить дублирующиеся строки из таблицы, используется ключевое слово DISTINCT: |
|
proc sql;
select distinct AGE
from demo;
quit;
|
Можно заметить, что пациенты под номерами 8004013 и 8014004 одинакового возраста (64 лет). Идентичное дублирование в возрасте для 8004014 и 8012006 (54 года). Поэтому с помощью DISTINCT нам удалось исключить повторения.
| Оператор DISTINCT касается всех переменных, которые идут после него: |
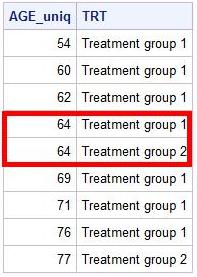
|
proc sql;
select distinct AGE as AGE_uniq,TRT
from demo;
quit;
|
В этом случае, наша таблица уникальна не только по возрасту, а и по лечащей группе. Также можно использовать оператор as для создания и сохранение в таблице новых переменных (в нашем случае переменной AGE_uniq присвоили значение переменной AGE).
Для того, чтобы определить условие, которому должны удовлетворять выбранные данные, используйте оператор WHERE. Все ранее изученные логические операторы (and, or, not) и операторы сравнения (lt, eq, gt…) также можно применять в операторе WHERE. Обратите внимание, что в операторе WHERE можно указать переменные, которые уже имеются в дата сете, а не создаются на процедурном шаге.
Например, вы сохранили константу в переменную SITEID и используете эту же переменную для условия выборки:
proc sql;
select AGE ,TRT, "1000" as SITEID
from demo
where SITEID="1000";
quit;
После выполнения этой процедуры, в log файле у вас будет следующая ошибка:
ERROR: The following columns were not found in the contributing tables: SITEID.
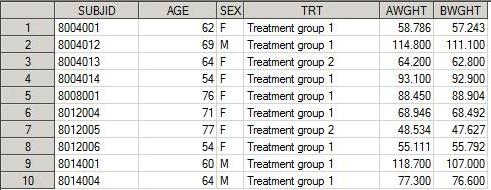
Рассмотрим как с помощью PROC SQL можно суммировать данные. Для этого используем дата сет demo2, в котором BWGHT – вес до начала приема лекарства, AWGHT – вес на одном из визитов во время приема препарата. Нужно определить средний вес для каждого пациента на всем исследовании.
Дата сет demo2:
proc sql;
select *, mean(BWGHT, AWGHT) as mean_value
from demo2;
quit;
Для решения этой задачи используем функцию mean, значение которой сохраняем в переменную mean_value. В результате получаем таблицу:
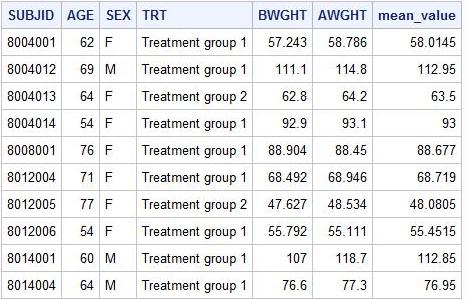
Заметим, что если у вас более одного аргумента для функции суммирования (как в нашем случае BWGHT и АWGHT) , то функция работает подобно шагу данных (вычисляет среднее для каждого наблюдения).
Если же вы укажете только одну переменную, то производится вычисление только для этой переменной.
proc sql;
select *, mean(BWGHT) as mean_base
from demo2;
quit;
Результат:
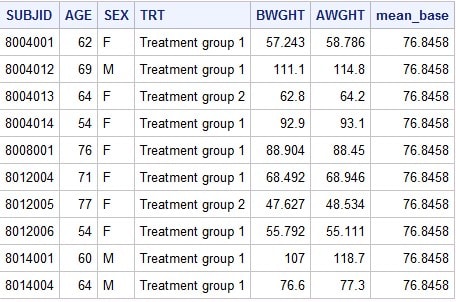
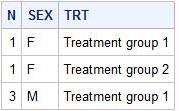
В следующей задаче, нам необходимо из дата сета demo2 найти количество пациентов в зависимости от пола и лечащей группы, возраст которых 60-70 лет.
proc sql;
select count(SUBJID) as N, SEX, TRT
from demo2
where AGE in (60:70)
group by SEX, TRT;
quit;
Используем функцию count для подсчета количества пациентов, которое в свою очередь сохраняем в переменную N. Так же для понимания какому полу и какой treatment group соответствует каждое N, указываем их в select. С помощью оператора where определяем возрастные рамки, и группируем по полу и лечащей группе.
Для сохранения всех результатов, полученных с помощью PROC SQL, воспользуйтесь командой CREATE TABLE name_of_dataset AS.
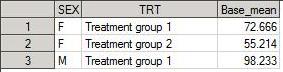
В качестве примера, создадим, дата сет BASE_TRT, в котором будет храниться среднее значение (под форматом 8.3) переменной BWGHT для каждого пола и каждой treatment group:
proc sql;
create table BASE_TRT as
select SEX, TRT, mean(BWGHT) as Base_mean format=8.3
from demo2
group by SEX,TRT;
quit;
Полученный дата сет BASE_TRT:
Merge дата сетов с помощью PROC SQL
С помощью PROC SQL также можно делать мердж нескольких датасетов. Рассмотрим основные способы.
У нас есть 2 дата сета: demo и cm

Demo
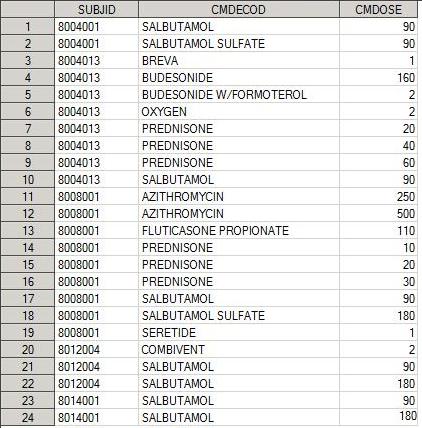
Cm
Inner Join
Это слияние двух дата сетов по переменным, значение которых есть одновременно в двух дата сетах.
Сделаем мердж дата сета demo и cm по SUBJID:
proc sql; create table inner as select A.*, B.CMDECOD, B.CMDOSE from demo as A, cm as B where a.subjid=b.subjid; quit;
С помощь команды select, указываем на переменные, которые нам надо сохранить в дата сет после слияния, а также переменные по каторым мы делаем join. Обратите внимание, что в следующей строке мы объявляем, какие дата сеты мы будем использовать. Дата сет demo мы обозначаем как А, cm как В. Это удобно для выбора переменных, а также необходимо для условия слияния. A.* - все элементы из дата сета demo, а обозначение B.CMDECOD, B.CMDOSE указывает на то, что эти переменные из дата сета cm. Заметим, что переменная SUBJID, по которой собственно и делается join в команде select указана только один раз (A.*).
where a.subjid=b.subjid является условием слияния дата сетов (каждому SUBJID из demo соответствует SUBJID из cm).
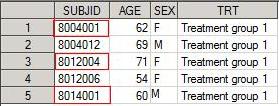
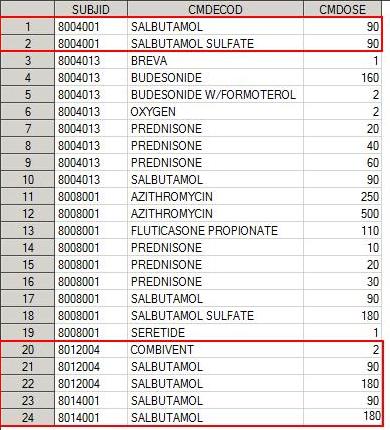
Полученный дата сет inner:
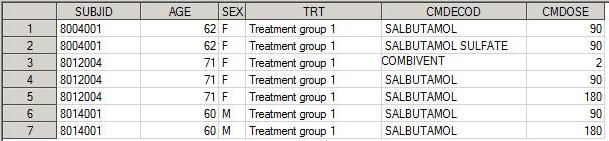
Left Join
Left join – слияние, в котором выбираются элементы из всех наблюдений в первом (левом) наборе данных независимо от значений on - переменной (SUBJID) во втором дата сете. Из второго дата сета присоединяются только те наблюдения, которые соответствуют SUBJID первого дата сета. Если ключ-переменная есть в левом дата сете, и нет ее в правом, то все переменные второго дата сета заполняются пустыми значениями.
proc sql; create table left1 as select A.*, B.CMDECOD, B.CMDOSE from demo as A left join cm as B on a.subjid=b.subjid; quit;
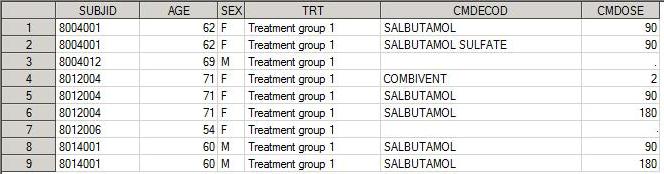
Дата сет left1
Right Join
Принцип работы слияния такой же, как и предыдущий, только теперь все присоединяется ко второму дата сету:
proc sql; create table right1 as select A.SEX, A.TRT, B.SUBJID, B.CMDECOD, B.CMDOSE from demo as A right join cm as B on a.subjid=b.subjid; quit;
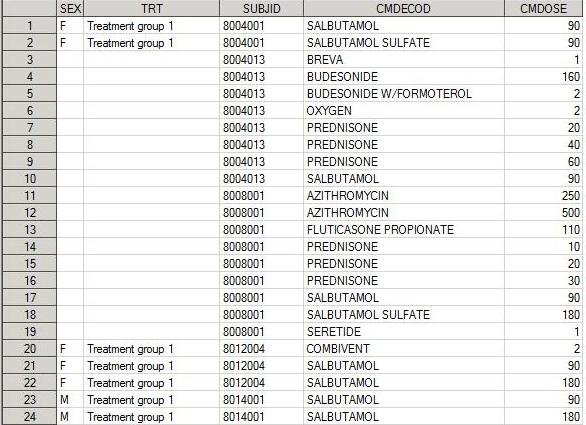
Dataset right1
Создание макро переменных с помощью PROC SQL
Задача: из дата сета demo (стр. 1) cоздать макро переменные N_TRT1 и N_TRT2, в которых будет храниться количество уникальных пациентов на каждую TRT группу.
proc sql noprint; select count(distinct SUBJID) into :N_TRT1 from demo where TRT="Treatment group 1"; select count(distinct SUBJID) into :N_TRT2 from demo where TRT="Treatment group 2"; quit; %put "Number of trt1:&N_TRT1"; %put "Number of trt2:&N_TRT2";
Рассмотрим решение этой задачи.
- Опция noprint указывает на то, чтобы не выводить результат процедуры в окно «Results Viewer»;
- count(distinct SUBJID) - количество уникальных пациентов;
- into :N_TRT1 - значение сохраняется в макро переменную N_TRT1;
- В нашем случае, мы отдельно создаем макро переменную для каждой treatment группы.
- После вызова %put в лог файле можно увидеть значение макро переменных:
- 662 %put "Number of trt1:&N_TRT1";
"Number of trt1: 8" - 663 %put "Number of trt2:&N_TRT2";
"Number of trt2: 2"
- 662 %put "Number of trt1:&N_TRT1";
Этими макро переменными удобно пользоваться в заголовках колонок, в тайтлах таблиц и т.д..
Дополнительные материалы: