По сути PROC REPORT является усовершенствованной версией PROC PRINT. В настоящее время этот уникальный продукт сочетает в себе возможности PROC PRINT, SORT, FREQ и MEANS. Из-за смеси своих специальных возможностей, PROC REPORT зачастую является самым простым способом сгенерировать элегантный data-листинг или сводную таблицу. В этом уроке мы рассмотрим наиболее распространённые варианты применения этой процедуры.
PROC REPORT
Общий обзор
PROC REPORT представляет собой очень мощное, и в тоже время простое средство, которое используется для создания довольно «привлекательных» отчётов. Т.к. программист сам контролирует порядок вывода, а также содержимое каждой колонки – процедура является очень гибкой и удобной.
Каждый SAS программист знает, что подсчёт descriptive statistics либо frequency counts – это лишь одна из составных частей нашей работы. Просто голые числа никому не интересны, а в некоторых случаях даже бессмысленны. Именно поэтому при изучении PROC MEANS и PROC FREQ я приводила примеры форматирования результатов. И именно эти «подготовленные» результаты мы научимся представлять в виде полноценного отчёта, на основе которого уже можно будет делать выводы об анализируемых данных не только вам, но и собственно заказчикам. Как правило заказчик в первую очередь смотрит именно на сводные таблицы и data-листинги, поэтому впечатление о вас как о профессионалах формируется исходя из качества этих самых таблиц и листингов. Ну а качество в свою очередь напрямую зависит от того, насколько хорошо вы освоите данный урок.
Также в этом уроке мы научимся сохранять отчёты, сгенерированные PROC REPORT в простой текстовый файл или RTF файл.
Базовый синтаксис процедуры
Базовый синтаксис процедуры такой:
PROC REPORT <option(s)>; WHERE <condition>; BY <DESCENDING> variable-1 <… <DESCENDING> variable-n><NOTSORTED>; COLUMN column-specification(s); DEFINE report-item / <option(s)>; BREAK location break-variable / <option(s)>; RUN;
Давайте рассмотрим назначение каждого оператора (выделены синим выше). Итак,
- PROC REPORT: инициализирует вызов процедуры; генерирует отчёт на основе input data set;
- WHERE: осуществляет отбор по условию (
) из input data set; - BY: создает отдельную секцию отчёта для каждой BY-группы; как видно из базового синтаксиса – by-переменные могут быть представлены не только в порядке возрастания, но и нисходящем порядке, указывая ключевое слово DESCENDING перед названием by-переменой; также можно воспользоваться ключевых словом NOTSORTED после имени by-переменной, в этом случае информация будет представлена в том порядке, в котором значения by-переменной идут в input data set; при использовании by-переменных input data set должен быть предварительно по ним отсортирован;
- COLUMN: указывает список выводимых переменных, а также порядок их следования в отчёте, т.е. в каком порядке переменные будут перечислены в оператора COLUMN – в таком порядке вы их увидите в отчете – это важно;
- DEFINE: описывает каким образом будут использоваться и отображаться переменные, указанные в операторе COLUMN; порядок описания COLUMN-переменных в операторе DEFINE не имеет никакого значения, но давайте возьмем за правило описывать переменные в DEFINE именно в том порядке, в котором они были объявленные в COLUMN;
- BREAK: указывает переменную, перед/после каждого уникального значения которой будет вставлена пустая строка, либо страница;
- RUN: выполняет ранее введенные операторы SAS.
Далее рассмотрим описание опций по каждому оператору:
| Statement | Option | Description |
|---|---|---|
| PROC REPORT | DATA = SAS-data-set | Указывает исходный набор выводимых данных (input data set) |
| WINDOWS | NOWINDOWS | Выбираем в каком режиме сработает PROC REPORT – с открытием окна | |
| Управление общим форматом вывода | ||
| CENTER | NOCENTER | Указывает каким образом выводить данные в отчёте – по центру (CENTER) либо по левому краю (NOCENTER) | |
| FORMCHAR = 'formatting-character(s)' | Указывает список символов, которые будут использованы для прорисовки разделительных линий в отчёте. В наших проектах по умолчанию используются такие символы как |_---|+|---+=|-/\<>* | |
| LS = line-size | Определяет длину строки выводимого отчёта (в символах). В наших проектах по умолчанию LS = 140 символов. | |
| PS = page-size | Определяет количество строк, выводимых на одну страницу. Применяется только для LISTING outputs. В наших проектах по умолчанию PS = 45 строк. | |
| SPACING = space-between-columns | Определяет расстояние (в символах) между колонками отчёта. Применяется только для LISTING outputs. | |
| STYLE | Применяется для вывода в формате RTF. Задает стиль отчёта. Подробности изучим ниже на примере. | |
| Управление заголовками колонок | ||
| NOHEADER | Если вы укажете эту опцию – SAS не станет выводить заголовки колонок | |
| SPLIT = 'character' | Указывает split-символ, который позволит разбивать заголовки колонок на несколько строк | |
| HEADLINE | Подчёркивает все заголовки колонок, а также расстрояния между ними. Применяется только для LISTING outputs. | |
| HEADSKIP | Выводит пустую строку под всеми заголовками колонок. Применяется только для LISTING outputs. | |
| Выравнивание значений в колонках, а также заголовки колонок | ||
| DEFINE | LEFT | CENTER | RIGHT | Задает выравнивание значений в колонках по левому краю (LEFT), по центру (CENTER) либо по правому краю (RIGHT) |
| ‘column-header’ | Задает заголовок для выводимой колонки | |
| Управление внешним видом выводимой колонки | ||
| FORMAT = format | Накладывает на выводимую переменную заранее определенный SAS format | |
| ORDER = DATA | FORMATTED | FREQ | INTERNAL |
Упорядочивает значения ORDER или GROUP переменных согласно выбранному порядку:
|
|
| SPACING = horizontal-positions | Используется для LISTING output. Задает количество символов, которое будет вставлено перед выводом текущей колонки. Так, например, для вывода самой первой колонки в отчёте spacing будет равен 0, т.е. вывести колонку, не отступая от левого края. | |
| WIDTH = column-width | Указывает ширину выводимой колонки (в символах для LISTING ouput). Помним, что сумма ширин всех колонок + spacings между колонками должны сходиться к тому числу, что записано в опции LS оператора PROC REPORT для LISTING output. | |
| STYLE | Применяется для вывода в формате RTF. Задает стиль вывода конкретной колонки. Тут обычно задают ширину колонки в %. Подробности изучим ниже на примере. | |
| Управление использованием выводимой колонки | ||
| DISPLAY | Определяет выводимую переменную, как DISPLAY колонку, т.е. значения переменной будут просто «показаны» в отчёте | |
| GROUP | Определяет выводимую переменную, как GROUP колонку, т.е. в процессе формирования отчёта одинаковые значения переменной будут сгруппированы | |
| ORDER | Определяет выводимую переменную, как ORDER колонку, т.е. в процессе формирования отчёта значения переменной будут отсортированы в порядке, указанном в опции ORDER = | |
| FLOW | Дает возможность “разнести” длинный текст в колонке на несколько строк. Если ваши значения не влезут в определённую вами длину колонки (WIDTH = ) и вы не укажете опцию FLOW, то выводимы текст обрежется. Также опция может быть использована для переноса значений переменной на несколько строк в местах, где встречается SPLIT символ | |
| ID | Указывает, что выводимая переменная – это ID-переменная. Удобно использовать в случаях, когда информация не может быть представлена на одной странице, и чтобы не повторять определение колонок на след. странице – можно указать начальные колонки, как ID, тогда SAS повторит их за вас автоматически на всех последующих страницах. | |
| NOPRINT | Указывает, что данную колонку не нужно выводить в отчёт. NOPRINT-колонки (они же переменные), как правило используют для сортировки данных прямо в PROC REPORT. | |
| BREAK | location |
Указывает в каком месте нужно вставить новую строку и/или страницу. Возможные значения:
|
| break-variable | Указывает имя переменной, перед/после каждого встреченного значения которой будет вставлен BREAK. Переменная должна быть предварительно объявлена в операторе COLUMN, а также описана как ORDER или GROUP в операторе DEFINE. | |
| SKIP | Вставляет пустую строку BEFORE/AFTER each break-variable’s value. Применяется для LISTING outputs. | |
| PAGE | Вставляет новую страницу BEFORE/AFTER each break-variable’s value. Применяется как для LISTING outputs, так и для RTF outputs. Для корректной работы с RTF нужно указать опцию STARTPAGE = YES в ODS RTF statement. | |
Вызов процедуры и описание результатов вывода
За основу возьмем все тот же input data set SCORES, содержащий информацию об успеваемости учеников одного класса. Сохраним данные в input SAS data set используя DATA STEP и оператор DATALINES:
data scores; infile datalines dlm='|'; length name $10 subject $20 score 8; input name subject score; datalines; John|Math|98 John|English|76 John|Biology|81 John|Physics|69 John|Economics|79 Tony|Math|65 Tony|English|34 Tony|Biology|87 Tony|Physics|56 Tony|Economics|90 Jeff|Math|41 Jeff|English|45 Jeff|Biology|56 Jeff|Physics|78 Jeff|Economics|34 ; run;
Выполним DATA STEP. Получим input data set вида:
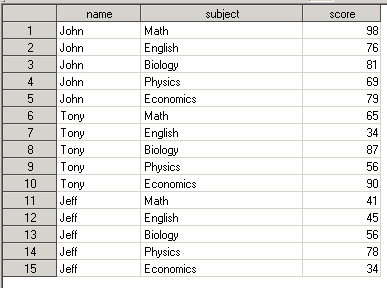
Теперь давайте выведем информацию из датасета SCORES в окно REPORT. Для этого вызовем PROC REPORT без опций и оператора COLUMN (т.е. SAS распечатает все переменные, которые имеются в датасете):
proc report data=scores;
run;
Результат выполнения процедуры можно посмотреть в окне REPORT:
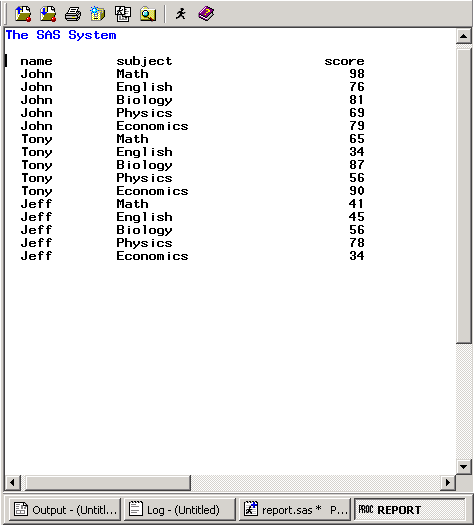
Итак, что же мы видим. В окно REPORT вывелась вся информация, которая содержится в датасете SCORES. Заголовки колонок совпадают с именами переменных, но различить визуально где заголовки, а где сами данные - трудно. Общее впечатление – вывод ничем не отличается от использования PROC PRINT, поэтому дальше будем работать с процедурой без вывода в окно REPORT, а сам отчёт сразу сохраним в простой текстовый файл.
Давайте кастомизируем наш вызов PROC REPORT таким образом, чтобы:
- каждая колонка имела свой заголовок, а не только название выводимой переменной;
- добавим заголовки и сноски, чтобы человек далёкий от того, что это за данные он видит сразу понял, что к чему;
- данные по каждому студенту были зрительно отделены друг от друга пустой линией;
- тело отчёта было отделено от заголовков и сносок линиями подчёркивания;
- отчёт сохранился в обычный текстовый файл с расширением .lst;
Для этого выполним такой код:
ods listing file="U:\SAS Training Project\list\Kristina Levi (teacher)\REPORT.lst"; title1 " Listing of Students' Progress"; title2 "____________________________________________________________________________________________________________________________________"; footnote1 "____________________________________________________________________________________________________________________________________"; footnote2 "Note: Students' scores for the following subjects are listed: Math, English, Biology, Economics"; proc report data=scores nowd nocenter split='@' headline headskip spacing=0 ls=132 ps=45; column name subject score; define name/order order=internal "Student's@Name" left width=44; define subject/display "Subject" left width=44; define score/display "Subject's@Score" left width=44; break after name/skip; run;
Итак, что же мы видим:
- Вызов PROC REPORT обрамлен вызовами оператора ODS LISTING. В первом вызове мы указали куда именно сохранить наш отчёт. Во втором «попросили» SAS закрыть направление вывода, чтобы больше туда ничего не записалось.
- Далее мы видим вызовы оператора TITLE, который создаст нам сам заголовок отчёта (TITLE1) и нарисует линию подчёркивания, которая зрительно отделит отчёт от заголовка (TITLE2).
- Затем идут операторы FOOTNOTE для формирования сносок. Первый вызов рисует линию подчёркивания после тела отчёта (FOOTNOTE1). Второй вызов выводит текстовую информацию по нашему отчёту (FOOTNOTE2).
-
В операторе PROC REPORT указаны такие опции:
- NOWD – т.е. нам не нужно открывать окно REPORT в редакторе, на результаты мы будем смотреть уже в файле.
- NOCENTER – т.е. не нужно выводить отчёт посреди страницы. Отчёт будет выведен по левому краю страницы.
- SPLIT = '@' – т.е. мы будем использовать именно этот символ, для разбиения заголовков колонок на несколько строк.
- HEADLINE – выводим линию подчёркивания под заголовками.
- HEADSKIP – вставляем пустую строку перед телом отчёта, чтобы зрительно отделить данные от заголовков.
- SPACING = 0 – устанавливаем расстояние между колонками равным нулю.
- LS = 132 – устанавливаем ширину выводимой страницы в 132 символа.
- PS = 45 – устанавливаем количество строк, выводимых на одной странице.
- В операторе COLUMNS указываем какие переменные (и в каком порядке) мы хотим видеть в отчёте.
-
В операторах DEFINE описываем как именно будут выглядеть данные в каждой колонке. Давайте разбираться на примере DEFINE NAME:
- Опция ORDER говорит о том, что переменная NAME будет являться ORDER переменной, т.е. в отчёте мы увидим только уникальные значения этой переменной
- Опция ORDER = INTERNAL говорит о том, что значения переменной NAME будут отсортированы прямо в PROC REPORT в порядке возрастания неформатированного значения.
- “Student’s@Name” определяет заголовок колонки. Тут можно увидеть тот самый split-символ @ - т.е. в месте, где она встретилась SAS сделает перевод строки.
- Опция LEFT указывает, что заголовки колонок, а также значения колонок будут выровнены по левому краю.
- Опция WIDTH = 44 определяет ширину, которую будет занимать колонка в отчёте. Помним, что сумма ширин всех колонок должна сходиться к значению, указанному в LS (line size).
- В операторе BREAK указываем переменную NAME, после (AFTER) каждого уникального значения которой будет вставлена пустая строка (SKIP).
После выполнения вышеприведенного кода отчёт будет выглядеть так:
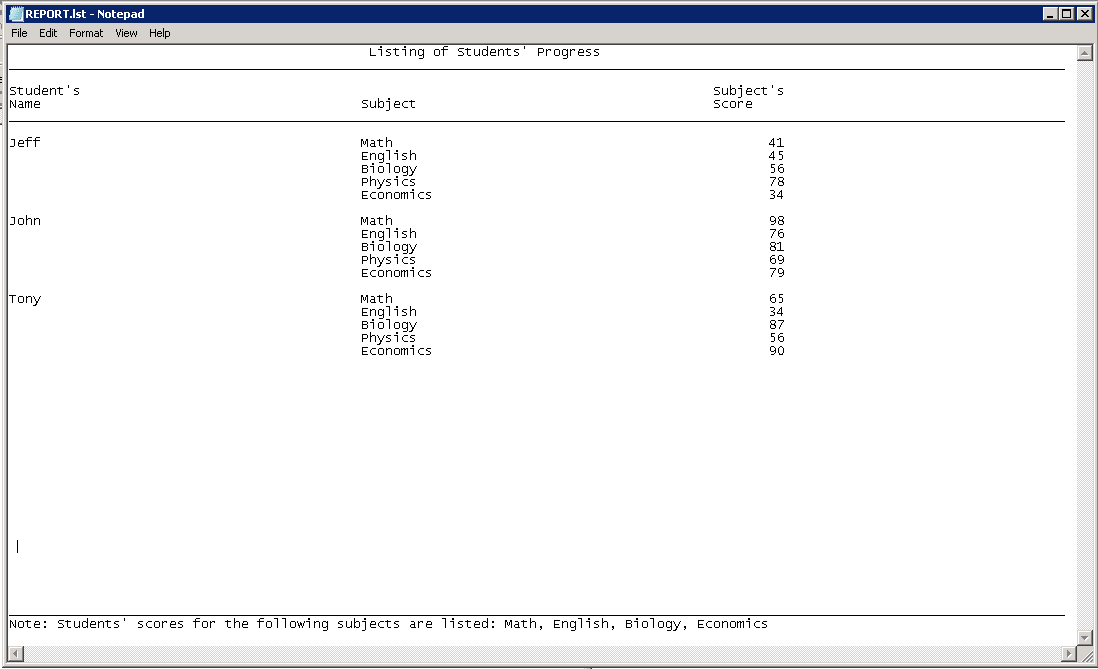
С выводом в обычный текстовый файл разобрались, теперь давайте перейдем к выводу в формате RTF.
Для этого выполним такой код:
ods rtf file="c:\Users\stina\Desktop\REPORT.rtf" style=minimal startpage=yes; options orientation=landscape; title1 justify=c "Listing of Students' Progress"; footnote1 justify=l "Note: Students' scores for the following subjects are listed: Math, English, Biology, Economics"; proc report data=scores nowd center split='@'; column name subject score; define name/order order=internal "Student's@Name" left style=[width=30%]; define subject/display "Subject" left style=[width=30%]; define score/display "Subject's@Score" left style=[width=30%]; compute after name; line ''; endcomp; run; ods rtf close;
- Вызов PROC REPORT обрамлен вызовами оператора ODS RTF. В первом вызове мы указали куда именно сохранить наш отчёт, а также какой стиль отчёта использовать. Я выбрала стиль MINIMAL, но на самом деле есть около 20 разных RTF стилей, которые по умолчанию поддерживает SAS. Кому интересно – читаем в SAS help. Также видим опцию STARTPAGE = YES, которая позволяет разбивать наш отчёт на страницы в тех местах, где нам это может понадобиться. Во втором вызове ODS RTF мы «попросили» SAS закрыть направление вывода, чтобы больше туда ничего не записалось.
- Далее устанавливаем ориентацию страниц в нашем отчёте. Как правило все отчёты делаются в LANDSCAPE формате.
- Далее мы видим вызов оператора TITLE, который создаст нам сам заголовок отчёта (TITLE1). При использовании ODS RTF мы также можем менять позицию заголовка при помощи опции JUSTIFY. В данном примере заголовок выровнен посредине страницы. В отличии от LISTING output нам больше не нужно руками рисовать линию подчёркивания, т.к. данные по умолчанию будут выведены в виде таблицы с границами.
- Затем идет оператор FOOTNOTE. В отличии от LISTING output нам опять-таки не нужно рисовать линию подчёркивания.
-
В операторе PROC REPORT указаны такие опции:
- NOWD – т.е. нам не нужно открывать окно REPORT в редакторе, на результаты мы будем смотреть уже в файле.
- CENTER – т.е. вывести таблицу отчёта по центру страницы.
- SPLIT = '@' – т.е. мы будем использовать именно этот символ, для разбиения заголовков колонок на несколько строк.
- В операторе COLUMNS указываем какие переменные (и в каком порядке) мы хотим видеть в отчёте.
-
В операторах DEFINE описываем как именно будут выглядеть данные в каждой колонке. Давайте разбираться на примере DEFINE NAME:
- Опция ORDER говорит о том, что переменная NAME будет являться ORDER переменной, т.е. в отчёте мы увидим только уникальные значения этой переменной.
- Опция ORDER = INTERNAL говорит о том, что значения переменной NAME будут отсортированы прямо в PROC REPORT в порядке возрастания неформатированного значения.
- “Student’s@Name” определяет заголовок колонки. Тут можно увидеть тот самый split-символ @ - т.е. в месте, где она встретилась SAS сделает перевод строки.
- Опция LEFT указывает, что значения в колонках будут выровнены по левому краю. Заголовки же по умолчанию будут выведены по центу (в отличии от LISTING output, где опция LEFT выравнивает и заголовки)
- STYLE = [WIDTH = 30%] задает процентное отношение ширины колонки к ширине всего отчёта. В отличии от LISTING output величина измеряется не в символах, а в процентах. Просто опция WIDTH = в RTF output не работает. /li>
- Т.к. RTF output не поддерживает опцию SKIP в операторе BREAK – мы вставили COMPUTE block, который после (AFTER) каждого уникального значения переменной NAME вставит в отчёт пустую строку (LINE ''). Подробнее о COMPUTE block читайте самостоятельно в SAS help.
Теперь давайте откроем наш REPORT.rtf и посмотрим, что получилось:

Сразу можно заметить, что RTF file намного привлекательней обычного текстового, именно поэтому практически все реальные отчёты делаются именно в формате RTF.
Код программы создания отчёта в форматах .lst и .rtf:
data scores; infile datalines dlm='|'; length name $10 subject $20 score 8; input name subject score; datalines; John|Math|98 John|English|76 John|Biology|81 John|Physics|69 John|Economics|79 Tony|Math|65 Tony|English|34 Tony|Biology|87 Tony|Physics|56 Tony|Economics|90 Jeff|Math|41 Jeff|English|45 Jeff|Biology|56 Jeff|Physics|78 Jeff|Economics|34 ; run; * Creating .lst report; ods listing file="U:\SAS Training Project\list\Kristina Levi (teacher)\REPORT.lst"; title1 " Listing of Students' Progress"; title2 "____________________________________________________________________________________________________________________________________"; footnote1 "____________________________________________________________________________________________________________________________________"; footnote2 "Note: Students' scores for the following subjects are listed: Math, English, Biology, Economics"; proc report data=scores nowd nocenter split='@' headline headskip spacing=0 ls=132 ps=45; column name subject score; define name/order order=internal "Student's@Name" left width=44; define subject/display "Subject" left width=44; define score/display "Subject's@Score" left width=44; break after name/skip; run; * Creating .rtf report; ods rtf file="c:\Users\stina\Desktop\REPORT.rtf" style=minimal startpage=yes; options orientation=landscape; title1 justify=c "Listing of Students' Progress"; footnote1 justify=l "Note: Students' scores for the following subjects are listed: Math, English, Biology, Economics"; proc report data=scores nowd center split='@'; column name subject score; define name/order order=internal "Student's@Name" left style=[width=30%]; define subject/display "Subject" left style=[width=30%]; define score/display "Subject's@Score" left style=[width=30%]; compute after name; line ''; endcomp; run; ods rtf close;
Дополнительные материалы: