Рассморим два датасета.

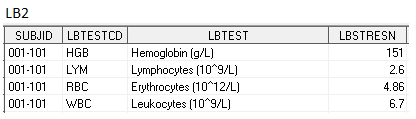
Оба они содержат одну и ту же информацию о результатах лабораторных тестов, но по структуре они кардинально отличаются друг от друга. В первом датасете, LB1, все данные на одной строке, для каждого теста – отдельная переменная. Во втором, LB2, несколько строк на пациента, для каждого теста – отдельная строка. Первый датасет горизонтальной структуры, а второй – вертикальной.
Немного усложним вид этих датасетов – добавим пациентов.
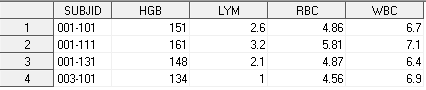
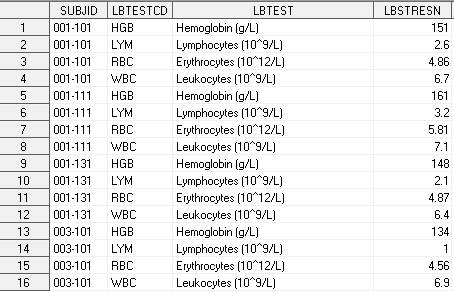
Основная цель данного урока – научиться изменять структуру данных датасета, другими словами, - транспонировать. В SAS для этого есть специальная процедура TRANSPOSE. Рассмотрим ее основные возможности.
Задача № 1.
Из датасета LB1 горизонтальной структуры получить датасет вертикальной структуры.
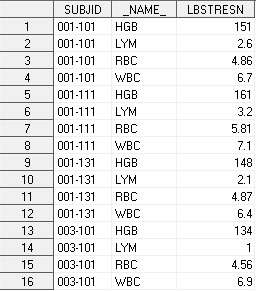
proc sort data=LB1; by SUBJID; run; proc transpose data=LB1 out=LB1_transp; by SUBJID; var HGB LYM RBC WBC; run;
В результате выполнения процедуры получим датасет LB1_transp:
Рассмотрим подробнее синтаксис.
proc transpose data=<входящий датасет> out=<результирующий датасет>; by <by-переменные>; var <переменные для транспонирования>; run;
Важно:
входящий датасет предварительно должен быть отсортирован по by-переменным.
by-переменные – переменные, которые SAS использует для формирования by-групп при транспонировании. Эти переменные не будут транспонированы – они останутся столбцами.
в оператор var задаются переменные для транспонирования. Имена этих переменных сформируют переменную _NAME_, а значения – переменную COL1 в итоговом датасете.
Задача № 2.
Получить из датасета LB2 вертикальной структуры датасет горизонтальной структуры.
Вспомним из предыдущего урока понятие ключа датасета. Для LB1 ключом будет SUBJID. Для LB2 ключ – это переменные SUBJID, LBTESTCD, поскольку любая комбинация значений этих переменных дает уникальную строку в датасете.
Выполним транспонирование:
proc sort data=LB2; by SUBJID; run; proc transpose data=LB2 out=LB2_transp2; by SUBJID; var LBSTRESN; id LBTESTCD; run;
В результате датасет LB2_transp имеет вид:
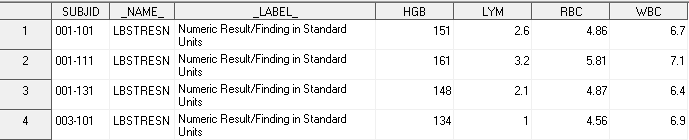
Обратите внимание, в синтаксисе процедуры появился новый элемент – оператор id.
proc transpose data=<входящий датасет> out=<результирующий датасет>; by <by-переменные>; var <переменные для транспонирования>; id <значения этих переменных формируют имена новых транспонированных переменных>; run;
Важно: переменные, заданные в операторе id, в сумме с by-переменными, должны являться ключом входящего датасета. Значения LBTESTCD ((“HGB” “LYM” “RBC” “WBC”) – теперь являются именами новых столбцов в транспонированном датасете.
В рассмотренных примерах мы всегда явно указывали SAS какие переменные станут by-переменными при транспонировании, какие переменные нужно транспонировать, а какие будут использоваться для именования новых переменных. Вообще говоря, синтаксис процедуры TRANSPOSE позволяет пользоваться операторами by, var и id как по отдельности, как в любой комбинации друг с другом, так и вовсе их опускать. На практике строго рекомендуется задавать явно все нужные операторы, поскольку мы работаем в условиях постоянного обновления и/или изменения данных. На одном и том же проекте всё время поступают новые данные, и одна и та же программа запускается несколько раз до тех пор, пока все данные для исследования не будут собраны. Очень важно стремиться сделать программу как можно более надежной и универсальной, минимизировать зависимость от входящих данных.
Для того, чтобы лучше ‘прочувствовать’ процедуру транспонирования рассмотрим еще несколько примеров.
1) Вызов процедуры транспонирования без операторов by, var, id:
proc transpose data=<входящий датасет> out=<результирующий датасет>; run;
В данном случае SAS в качестве var будет использовать все числовые переменные входящего датасета, а столбцы формировать по количеству строк. Рассмотрим на примере датасета Adverse.
proc transpose data=Adverse out=Adverse_transp; run;
Датасет Adverse_transp будет иметь вид:

Во входящем датасете Adverse две числовые переменные AESTDY и AEENDY – следовательно, сформировано две строки в итоговом датасете. Во входящем датасете Adverse одиннадцать строк, следовательно, сформировано одиннадцать столбцов в итоговом (COL1-COL11).
2) Вернемся к Задаче № 2 и выполним вызов процедуры транспонирования следующим образом:
proc transpose data=LB2 out=LB2_transp_2; by SUBJID; run;
Здесь будет действовать аналогичное правило, что и в примере с Adverse: в качестве var будут использоваться все числовые переменные входящего датасета, а столбцы будут формироваться по количеству строк в каждой by-группе SUBJID.
Попробуйте предугадать результат.
Совпало ли ваше предположение с изображением датасета ниже?
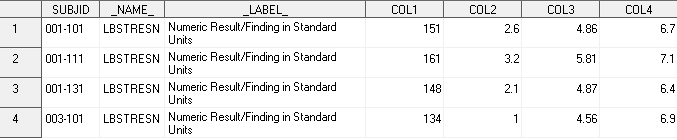
Как видите, полученный датасет LB2_transp_2 почти полностью совпадает с датасетом LB2_transp из Задачи № 2, за исключением того, что имена переменных не имеют таких ‘говорящих’ названий, как HGB, LYM, RBC, WBC. Ограничиваются ли на этом различия этих двух способов и какой все-таки стоит использовать мы обсудим на практическом занятии.
Дополнительные материалы:
Наиболее подробный синтаксис процедуры TRANSPOSE представлен по ссылке: